[Cross-posted from Connected by Data blog]
It’s been a busy week, not least because on Wednesday the project I was working on just before joining the Connected by data team, the Global Data Barometer, had its launch event. Alongside sharing, celebrating and reflecting on the Barometer, I’ve been digging deep into the development of a schema for our work to gather examples of collective data governance, and I’ve been thinking about potential events and convenings Connected by data might be part of in the coming year. Plus writing up some thoughts on what the implementation of social audits for India’s rural employment scheme in Andhra Pradesh can teach us about data governance, an initial bit of work on fundraising, and sending the first of many emails out to set up conversations with researchers I’m hoping to get some input from.
Cases, components and templates
I’ve been going through daily iterations to develop the structure for our case study database, taking a couple of different approaches to explore the right prompts, categories and structures that might create a useful library of collective data governance examples. I’ve been exploring:
- adding the classification categories, and library of methods, from Participedia as lookup tables, and using them as a starting point, but adding/expanding categories when needed. This has been particularly useful when it comes to methods, as when I’m considering coding a case against a given method I can check the detailed Participedia description to check whether the code is appropriate. I’ve also set-up one-click searching so I can see if the way I initially think a category should be used matches how it has been used by Participedia contributors.
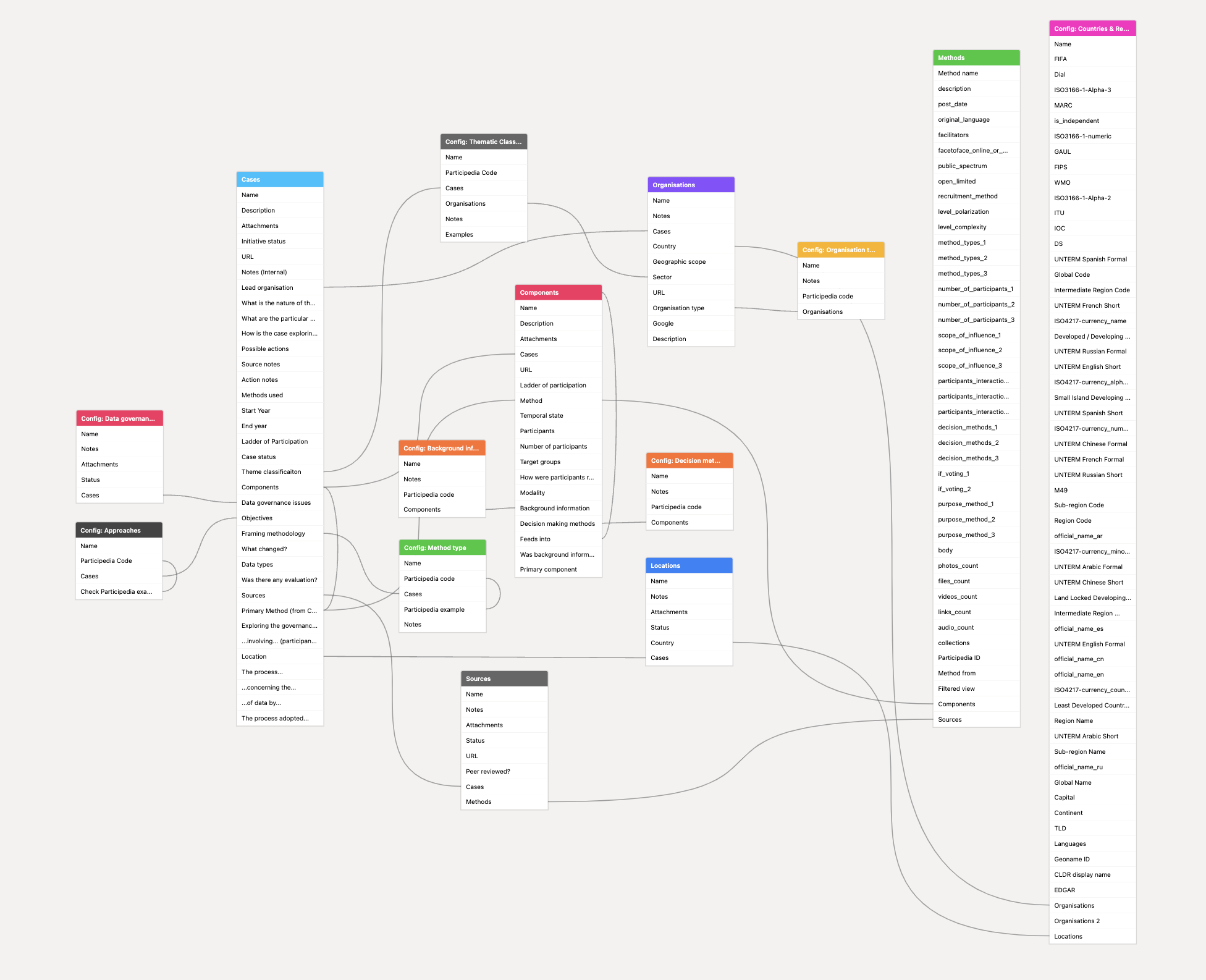
- coding up one case each day, and, if needed, modifying the case database schema to capture it better, before going back to re-code existing cases with the modifications. This has led to a ‘case’, ‘component’ and ‘method’ separation, so that any case of collective data governance might involve multiple components (e.g. design workshops; citizens jury & opinion polling), and these are each treated as particular cases of applying one or more participatory methods.
- drafting user stories (‘As an X I need Y so that Z’) to get a clearer sense of who the case database is for, and why. Thinking about the categories and data that users might actually want provides a useful counterbalance to the temptation to keep adding fields and more nuance when starting from reading diverse individual cases.
- writing out a templated summary paragraph for a case, and then working out the different variables needed to populate it. I’ve found it particularly useful to then frame the prompts in the case database around these sentence components, making it easier to think about how each category will be used when the case database is made available to others.

Next week I’ll be trying to get a few more cases documented, and then to start exploring strategies to make sure we cover a wide range of kinds of examples. Right now, the examples I’ve coded up, and those in the pipeline, have a strong leaning towards participatory processes that generate quite general recommendations, rather than processes that directly shape or make specific data governance decisions.
Events and outreach
I started the week by registering forRightsCon, which is taking place online from 6 – 10th June. It’s a long time since I’ve been able to focus on attending a conference, rather than juggling logging into one or two virtual sessions between other work, so I’m looking forward to that.
On our discord I raised the possibility of proposing a workshop to the 2022 Internet Governance Forum on Collective Data Governance, and I’ll be sketching that out more next week and looking to see if we have potential collaborators.
We’ve also been starting to think about other potential events or outreach activities we might want to plan for, and I’ve done some initial work on research fundraising strategy: although realising I’ve got quite a bit of work to do in order to identify how to best track research funding opportunities that are well-aligned with what we want to do.
Participation, pluralism and the public good
I put out a thread of reflections on the launch of the Global Data Barometer, but want to pick up in particular on one in these notes. The Barometer study is framed around “data for the public good”. One of the big conceptual challenges for the design of the project which was taking place in 2019/2020, was balancing demands for cross-country comparison, with an openness to diversity of data governance, provision and use practices.
In the introduction to the report we wrote:
“Fundamentally, our approach to the public good recognizes that the construction of public good is an ongoing, unfinished and contested process. “
And
“There are many publics, many different visions of how society should be organized, and there are many views on the goals we should individually and collectively work towards.”
But, particularly after starting to read a copy of Pluriverse – a post development dictionary which arrived last week, I’m not sure the more pluralist ambitions of the project were fully realised (understandably so). With hindsight, and the framings of Connected by data, I suspect some of that might have been addressed by giving greater prominence to questions of participation in metrics on data governance.
However, the Barometer method also required each metric to make reference to globally agreed norms or principles that would support country assessment on that point. This raises the interesting question of which global norms can already ground a collective and participatory model of data governance, and where there are significant policy gaps that might need addressing to put communities at the heart of data governance.
Other reading this week
- Bussu, S. et al. (2022) ‘Embedding participatory governance’, Critical Policy Studies – a compelling case to talk about embedding, rather than (or in addition to) institutionalising participatory governance, considering temporal (sustained over time), spatial (including presence of participation in different decision making spaces) and practice (habitual recourse to participatory process) dimensions of embeddedness.
- Van de Velde, L. (2022) Gender and Beneficial Ownership Transparency– paper from Open Ownership that explores some of the tensions in designing datasets, particularly when it comes to the potential for data collected for one task (beneficial ownership transparency), to be used for other public goods (e.g. promoting greater gender equity in enterprise). I’m curious how a more collective and participatory data governance lens might help address some of the issues the paper explores. But – ran out of time to explore that in depth.