[Cross-posted from Connected by Data blog]
A bumper two-week weeknotes today, as I was travelling last week (delightful Rail+Sail journey over to the Netherlands for a workshop with The Land Portal and Eurostar back for my first international trip in more than two years).
Researching collective narratives
The first thing to share is that I’ve just posted a call for a contract researcher (or team) to help us map out existing cases and media stories that talk about the impacts of data with a collective lens. We’re looking for an individual or team who can work between August and October searching out relevant stories (in focus areas of health, housing, debt and education), and build a framework for analysing how they address the collective dimensions of data impact.
The idea for this broad piece of mapping work came from our team day on Monday, where we looked at our current plans to commission a series of stories that help land the point that data needs to be governed collectively, rather than solely through individual consents and controls. We identified the need to both track down existing stories that we might amplify, and to understand more of how a collective lens is currently being adopted in popular stories about where data is being used or abused to help or harm communities.
Building a more diverse network
We had some discussions over whether to just reach out to researchers we know for this project, or whether to run an open call. The deciding factor was that we have a better chance of reaching a more diverse network of potential researchers with an open call, so, drawing on the fantastic guide Gavin Freeguard developed for MySociety on commissioning research we put together the full CfP and an application process.
We’ve setup the application form both for this particular opportunity, and to allow people to opt-in to being part of a ‘research pool’ we could draw on in future, and we’ve included a question that can help us to, when other factors are equal, to prioritise applications that help us use our position and privilege to help increase the diversity of the data policy field.
Are you a member of a community that is under-represented in work on data, digital and AI in the UK and Europe, and if so, how?
We are asking this question because we are particularly keen to work with a diverse and inclusive network of partners. Please only provide details you are comfortable with sharing.
I’ve also, alongside the obligatory data processing consent statement, included an experimental ‘collective data governance’ question. After all, people will be taking time to submit their information to this form, and might have ideas for what more they would like to see done with it.
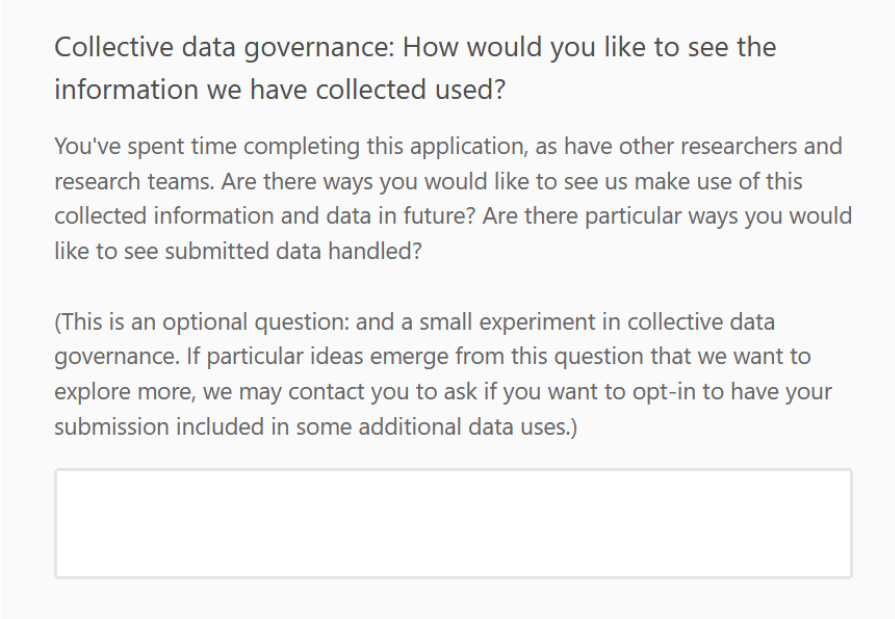
I have no idea what this will generate, if anything: but it will be interesting to see if it triggers any interesting ideas and responses.
Narratives and frames
As background to prepare the CfP, I spend some time going through an interesting paper from Skurka, Niederdeppe and Winett called ‘There’s More to the Story: Both Individual and Collective Policy Narratives Can Increase Support for Community-Level Action’ which uses an experimental design to explore whether individualised or collective narratives about food deserts, and narratives framed using left (equity) or right (loyalty) based language were more likely to solicit support for policy proposals based on a Social Determinants of Health (SDH) model. They present a detailed theoretical case for thinking through individual and collective storytelling, and mapping mechanisms such as identification, empathy, transportation, hostility and counterarguing that shape how an audience processes a story into policy support.
They highlight the concerns that “telling stories about individual cases – even when emphasising system and policy-level solutions- may inadvertently reinforce beliefs about personal responsibility for health, thereby undermining public willingness to support community-level efforts to address factors in the environment.”, although their experimental evidence does not appear to bear out this concern.
They also outline the distinction between narrative frameworks (which include a setting, characters, plot and moral), and message framing (the particular aspects of a story that are given emphasis). Critically, this highlights that both narrative frameworks, and message framing, may vary in their approach to an individual vs. collective dichotomy. For example, it is possible to have a narrative centred on an individual, but where the framing draws attention to collective level issues, or it is possible to have a narrative story told at the level of the community, but that emphasises issues of individual responsibility or action.
Whilst we’ve left things fairly broad in the CfP, just giving examples of the kinds of stories we hope to find, and planning to iterate with the selected researcher on the exact approach to categorising stories, I’m anticipating we might draw on some of the approaches and learning from the Global Voices Civic Media Observatory, which has developed a workflow for sourcing and annotating media stories to uncover the different frames at play.
Dialogue, decisions and design
I put the finishing touches to our expression of interest for the RSA’s call on Rethinking Public Dialogue this week, developed along with Jess Morely at OpenSAFELY. In a nutshell, our proposal is to explore a model of ‘dialogue on demand’: agile and inclusive mini-dialogues on data governance and research design decisions that are developed based on bottom-up input from affected groups, and that feed into both iterative data governance process refinement, and into focussed operational decision making.
Many of the public dialogues I’ve been looking at while building our participation cases database take the form of large-scale engagement activities with a broadly representative population, run over multiple weeks and months. Indeed, yesterday I had my first three hours as an observer for a current NHS AI focussed dialogue, run by IPSOS with the Open Data Institute, and that’s due to have three more three hour sessions (12 hours online dialogue time in all). Our working hypothesis for our RSA proposal is that, where this kind of model may be good at establishing general principles for how data should be governed, “A streamlined protocol for responsive informed dialogue, shaped by bottom-up inputs, can provide a scalable model for public engagement to be applied to live data and research governance.”.
Our proposal explores developing/adapting methods to map out the data flows involved in particular data-rich health research studies, and the potential outputs or outcomes from research, and then using visual and text artefacts from this mapping to solicit initial input from people who might be affected by a particular study, the data it uses, or the issues it might raise. From this, having potentially found communities affected by a given set of data governance decisions, we would then design shorter focussed dialogues rooted around very concrete cases, which, we hypothesise, will be more tangible than discussions about data sharing or governance ‘in general’, even if they can generate higher-level lessons for data governance practice.
Working out, in practice, how different publics can be engaged in data governance decisions is going to be really important to our work in the coming year, and is a piece of the work I’m particularly excited about.
We’ll hear more in the next few weeks about whether we can take this particular idea forward to a full proposal for the RSA, or whether we might need to find other ways to take it forward.
The intersection of data and AI governance
I’ve still got an outstanding task of trying to map where data and platform governance intersect, but this week I’ve been looking a bit more at how current work on data and AI governance might connect. Key to that was reading the new paper “Who Audits the Auditors? Recommendations from a field scan of the algorithmic auditing ecosystem” from Sasha Constanza-Chock, Inioluwa Deborah Raji, and Joy Buolamwini (who, as an aside I must note, are each some of the most inspiring, thoughtful and engaged scholars and humans anyone could hope to learn from). It has a number of useful insights for our thinking about the potential to embed collective data governance into organisational practice.
In their interviews with ten leading algorithmic auditors, and a survey of more than 150 people connected to algorithmic audit, they find significant gaps in the involvement of affected stakeholders in the algorithmic audit process, with just 30% of auditors saying that consider real-world harm to stakeholders when auditing algorithms, and only two providing examples of this. As a result, Sasha, Deborah and Joy recommend that_ “It should be a priority for regulators to ensure that audits include affected stakeholders, and for organisations to establish internal policy that promotes direct involvement of the stakeholders most likely to be harmed by AI systems.”_ going on to argue that, whilst participatory practice can be messy, “Solutions should be informed by the existing field of participatory design, and by the growing community of design justice practitioners, and should be supported by a field-wide investment in strategies to meaningfully engage community partners and support community-led processes for algorithmic accountability.”
The paper also describes some of the challenges that internal (first-party), or contracted (second-party) teams involved in algorithmic audit face, in terms of resistance of organisations to engaging with audit processes that might lead to a need to change profitable practices, or restrictions on making audit findings public. This resonates with themes I’ve found in Waldman’s Industry Unbound, around the way in which corporate structures can significantly inhibit the freedom of workers to insert public interests into private enterprise, and points to some of the significant challenges that efforts to embed collective and participatory models of data governance will face.
I’ve also got a few other FAccT papers on my reading list thanks to Catherine D’Ignazio’s fantastic thread that picks out a number of the key findings. In particular, as we explore the point in our Theory of Change (update on that coming soon) that addresses developing a community of practice, this piece on tech worker organising looks particularly important to consider.
Learning to govern
The last two Monday evenings I’ve been undertaking mandatory online training as a new school parent governor at my son’s school. In the UK, over a quarter of a million people volunteer as school governors, taking on a strategic and oversight role for finance, staffing and school development. The training, unsurprisingly, was heavy on running through all the processes and practical activities of governance: from making and writing up school observation visits, to plotting a calendar of policy reviews and a cycle of meetings setting and tracking progress against improvement plans. We also spent some time exploring the different structures of governing boards depending on the type of school (local authority, foundation, multi-school trust etc.), and the different kinds of governor (some appointed by parents, others by the local authority or trust, others from the staff body etc.).
Of course, school governance is very well established, and models have, more-or-less, settled into place (albeit with constant government reforms leading to updates and changes). But reflecting on this day-to-day bit of the national governance infrastructure, and it’s strengths and weaknesses in practice (in the break-out sessions there was a bit of opportunity hear from other governors about how well the theory presented in the training represents the reality in their schools), has me wondering what sort of scale and structure collective data governance at scale might take? Do we need 1000s of people on standing structures, with robust training and development programmes in place, to govern our shared data infrastructures? Or is collective data governance most often going to be a ‘function’ that fits into existing governance structures? Or are there new models entirely that can take the best of new technical approaches, while remaining inclusive, accessible and accountable?
Perhaps, most importantly, the training, and my recent conversations with other people who have experiences in school governance, highlight that governance in practice is, of course, about people. Personalities, a desire of a group to ‘get on’ and a recognition of the need to support resource-constrained teams, can all both help governance work well, and, at the same time, create barriers to effective scrutiny and accountability.
Other things
- Thanks to a kind invite from Asaf Lubin, I was on a Datasphere panel for the American Society of International Law last week, where our discussions touched on the interaction between agile regulation and public participation, and the need for data policy built on new narratives that understand the global and cross-boundary nature of contemporary data.
- For a couple of freelance projects with organisations that have defined their strategies around open data, I’ve been trying to write about some of the big trends of the last decade that have been reframing openness. I’ll hopefully have that in a blog post form soon.
- We had a team meeting day in Reading, which is written up in other’s team notes, and for which I spent some time digging into consultation responses to the Data Reform Bill (thanks to Peter Wells for this super helpful spreadsheet).
- I’ve been working on updates to our sectoral scoping on debt, again hopefully with more to share soon.
- I managed to follow most of the launch event for the Education Data Reality report from the Digital Futures Commission while on the train back from Amersfoort (super reliability of Dutch 4G) – which was packed full of useful insights to feed into our scoping of work on education as a sector. In short, there are a lot of questions to ask about how education data is being gathered and used, without a lot of good oversight right now (Note to self: explore whether the school governing board thinks about this at all!)