[Summary: extended notes from an unConference session]
At the recent data literacy focussed Open Government Partnership unConference day (ably facilitated by my fellow Stroudie Dirk Slater) I acted as host for a break-out discussion on ‘Artificial Intelligence and Data Literacy’, building on the ‘Algorithms and AI’ chapter I contributed to The State of Open Data book.
In that chapter, I offer the recommendation that machine learning should be addressed within wider open data literacy building. However, it was only through the unConference discussions that we found a promising approach to take that recommendation forward: encouraging a critical look at how AI might be applied at each stage of the School of Data ‘Data Pipeline’.
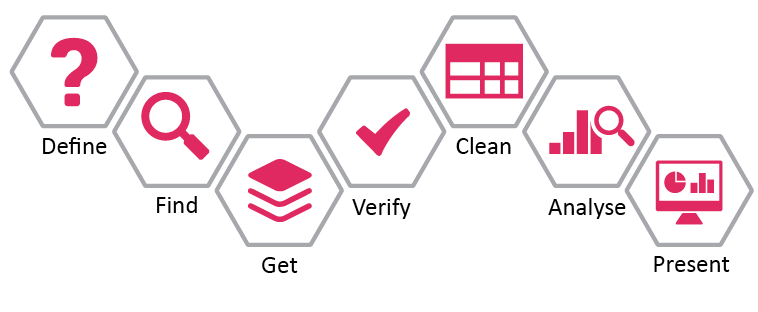
The Data Pipeline, which features in the Data Literacy chapter of The State of Open Data, describes seven stages for woking with data, from defining the problem to be addressed, through to finding and getting hold of relevant data, verifying and cleaning it, and analysing data and presenting findings.
Often, AI is described as a tool for data analysis (any this was the mental framework many unConference session participants started with). Yet, in practice, AI tools might play a role at each stage of the data pipeline, and exploring these different applications of AI could support a more critical understanding of the affordances, and limitations, of AI.
The following rough worked example looks at how this could be applied in practice, using an imagined case study to illustrate the opportunities to build AI literacy along the data pipeline.
(Note: although I’ll use machine-learning and AI broadly interchangeably in this blog post, as I outline in the State of Open Data Chapter, AI is a broader concept than machine-learning.)
Worked example
Imagine a human rights organisation, using a media-monitoring service to identify emerging trends that they should investigate. The monitoring service flags a spike in gender based violence, encouraging them to seek out more detailed data. Their research locates a mix of social media posts, crowdsourced data from a harassment mapping platform, and official statistics collected in different regions across the country. They bring this data together, and seek to check it’s accuracy, before producing an analysis and visually impactful report.
As we unpack this (fictional) example, we can consider how algorithms and machine-learning are, or could be, applied at each stage – and we can use that to consider the strengths and weaknesses of machine-learning approaches, building data and AI literacy.
- Define – The patterns that first give rise to a hunch or topic to investigate may have been identified by an algorithmic model. How does this fit with, or challenge, the perception of staff or community members? If there is a mis-match – is this because the model is able to spot a pattern than humans were not able to see (+1 for the AI)? Or could it be because the model is relying on input data that reflects certain bias (e.g. media may under-report certain stories, or certain stories may be over-reported because of certain cognitive biases amongst reporters)?
- Find – Search engine algorithms may be applying machine-learning approaches to identify and rank results. Machine-translation tools, that could be used to search for data described in other languages, are also an example of really well established AI. Consider the accuracy of search engines and machine-translation: they are remarkable tools, but we also recognise that they are nowhere near 100% reliable. We still generally rely on a human to sift through the results they give.
- Get – One of the most common, and powerful, applications of machine-learning, is in turning information into data: taking unstructured content, and adding structure through classification or data extraction. For example, image classification algorithms can be trained to convert complex imagery into a dataset of terms or descriptions; entity extraction and sentiment analysis tools can be used to pick out place names, event descriptions and a judgement on whether the event described is good or bad, from free text tweets, and data extraction algorithms can (in some cases) offer a much faster and cheaper way to transcribe thousands of documents than having humans do the work by hand. AI can, ultimately, change what counts as structured data or not. However, that doesn’t mean that you can get all the data you need using AI tools. Sometimes, particularly where well-defined categorical data is needed, getting data may require creation of new reporting tools, definitions and data standards.
- Verify – School of Data describe the verification step like this: “We got our hands in the data, but that doesn’t mean it’s the data we need. We have to check out if details are valid, such as the meta-data, the methodology of collection, if we know who organised the dataset and it’s a credible source.” In the context of AI-extracted data, this offers an opportunity to talk about training data and test data, and to think about the impact that tuning tolerances to false-positives or false-negatives might have on the analysis that will be carried out. It also offers an opportunity to think about the impact that different biases in the data might have on any models built to analyse it.
- Clean – When bringing together data from multiple sources, there may be all sorts of errors and outliers to address. Machine-learning tools may prove particularly useful for de-duplication of data, or spotting possible outliers. Data cleaning to prepare data for a machine-learning based analysis may also involve simplifying a complex dataset into a smaller number of variables and categories. Working through this process can help build an understanding of the ways in which, before a model is applied, certain important decisions have already been made.
- Analyse – Often, data analysis takes the form of simple descriptive charts, graphs and maps. But, when AI tools are added to the mix, analysis might involve building predictive models, able, for example, to suggest areas of a county that might see future hot-spots of violence, or that create interactive tools that can be used to perform ongoing monitoring of social media reports. However, it’s important in adding AI to the analysis toolbox, not to skip entirely over other statistical methods: and instead to think about the relative strengths and weaknesses of a machine-learning model as against some other form of statistical model. One of the key issues to consider in algorithmic analysis is the ’n’ required: that is, the sample size needed to train a model, or to get accurate results. It’s striking that many machine-learning techniques required a far larger dataset that can be easily supplied outside big corporate contexts. A second issue that can be considered in looking at analysis is how ‘explainable’ a model is: does the machine-learning method applied allow an exploration of the connections between input and output? Or is it only a black box.
- Present – Where the output of conventional data analysis might be a graph or a chart describing a trend, the output of a machine-learning model may be a prediction. Where a summary of data might be static, a model could be used to create interactive content that responds to user input in some way. Thinking carefully about the presentation of the products of machine-learning based analysis could support a deeper understanding of the ways in which such outputs could or should be used to inform action.
The bullets above give just some (quickly drafted and incomplete) examples of how the data pipeline can be used to explore AI-literacy alongside data literacy. Hopefully, however, this acts as enough of a proof-of-concept to suggest this might warrant further development work.
The benefit of teaching AI literacy through open data
I also argue in The State of Open Data that:
AI approaches often rely on centralising big datasets and seeking to personalise services through the application of black-box algorithms. Open data approaches can offer an important counter-narrative to this, focusing on both big and small data and enabling collective responses to social and developmental challenges.
Operating well in a datified world requires citizens to have a critical appreciation of a wide variety of ways in which data is created, analysed and used – and the ability to judge which tool is appropriate to which context. By introducing AI approaches as one part of the wider data toolbox, it’s possible to build this kind of literacy in ways that are not possible in training or capacity building efforts focussed on AI alone.