I was involved in setting up the Barometer project back in 2019/2020, and had the privilege of coming back into the project in December to work on the final report.
It’s already encouraging to see all the places the Barometer findings and data are being picked up, and whilst getting the report out feels like the finish line for, what has been, both marathon and sprint for the team – having the data out there for further analysis also feels like the starting line for lots of deeper research and exploration.
In particular, it feels like debates about ‘data for the public good’ have been developing at pace in parallel to the Barometer’s data collection, and I’m keen to see both how the Barometer data can contribute to those debates, and what future editions of the project might need to learn from the way in which data governance debates are shaping up in 2022.
[Summary: Fragments of reflection on the Decarbonisation and Decolonisation of AI]
I’ve spent some time this morning reading the ‘AI Decolonial Manyfesto’ which opens framed as “a question, an opening, a dance about a future of AI technologies that is decolonial”. Drawing on the insights, positions and perspectives of a fantastic collective authorship, it provides some powerful challenges for thinking about how to shape the future applications of AI (and wider data) technologies.
As I’ve been reading the Manyfesto on Decolonialisation in a short break from working on a project about Decabonisation – and the use of data and AI to mitigate and adapt to the pressing risks of climate breakdown, I find myself particularly reflecting on two lines:
“We do not seek consensus: we value human difference. We reject the idea that any one framework could rule globally.”
and
“Decolonial governance will recognize, in a way that Western-centric governance structures historically have not, how our destinies are intertwined. We owe each other our mutual futures.”
Discussions over the role of data in addressing the global climate crisis may veer towards proposing vast centralising data (and AI) frameworks (or infrastructures), in order to monitor, measure and manage low-carbon transitions. Yet – such centralising data infrastructures risk becoming part of systems that perpetuates historical marginalisation, rather than tools to address systemic injustice: and they risk further sidelining important other forms of knowledge that may be essential to navigate our shared future on a changing planet.
I’m drawn to thinking about the question of ‘minimum shared frameworks’ that may be needed both in national and global contexts to address the particular global challenge of the climate in which all our destines are intertwined. Yet, whilst I can imagine decentralised, (even decolonised?), systems of data capture, sharing and use in order to help accelerate a low-carbon transitions, I’m struggling at first-look to see how those might be brought into being at the pace required by the climate crisis.
Perhaps my focus for that should be on later lines of the Manyfesto:
“We seek to center the engineering, design, knowledge-production, and dispute-resolution practices of diverse cultures, which are embedded with their own value systems.”
My own cultural context, social role, academic training and temperament leaves me profoundly uncomfortable ending a piece of writing without a conclusion – even if a conclusion would be premature (one of the particular structures of the ‘Western male, white’ thought that perhaps does much harm). But, I suspect that here I need to simply take first steps into the dance, and to be more attuned to the way it flows…
Below I’ve shared a few quick notes in a spirit of open reflection (read mostly as ‘Yes, and…‘ rather than ‘No, but’):
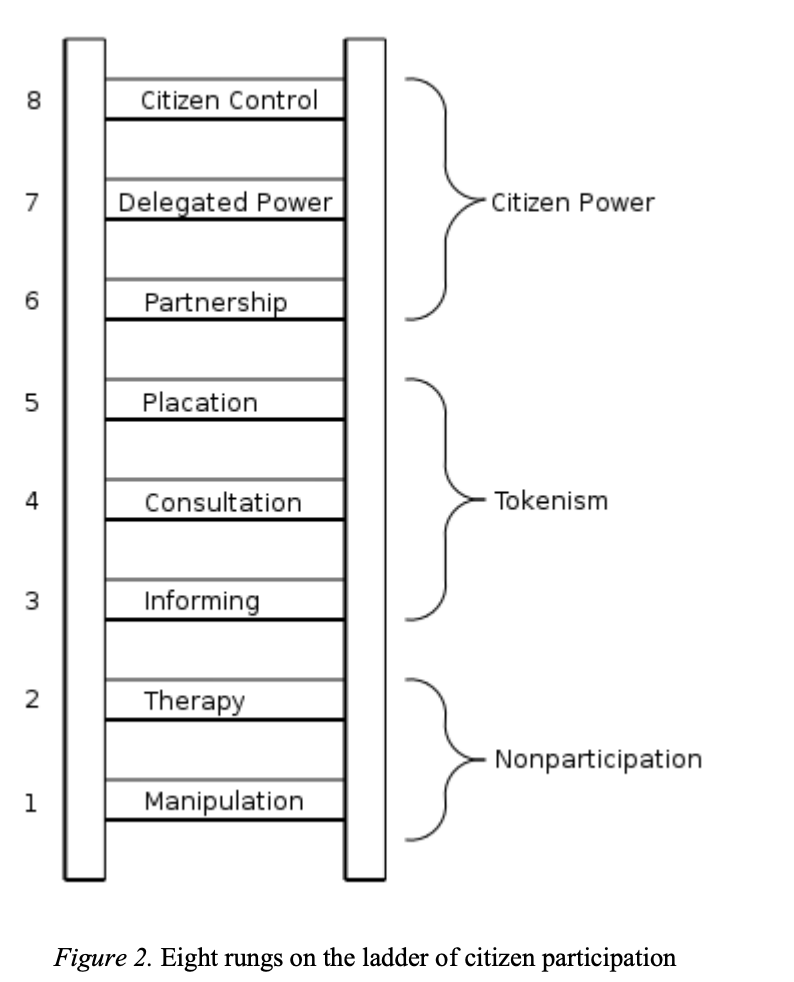
The ladder: Arnstein, Hart and Pathways of Participation
Arnstein’s ladder of participation.RSA ‘Remix’ of Arnstein
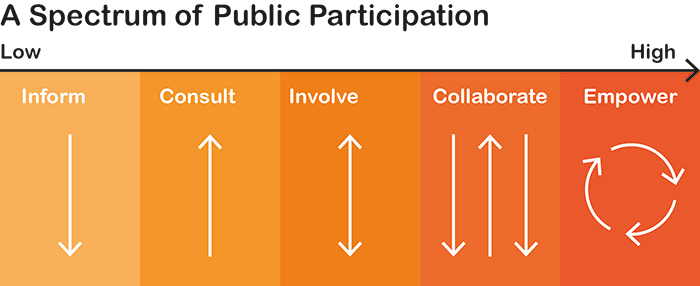
The report describes drawing on Sherry Arnstein’s ‘ladder of citizen participation’, but in practice uses an RSA simplification of the ladder into a five-part spectrum that cuts off the critical non-participation layers of Arnstein’s model. In doing this, it removes some of the key critical power of the original ladder as a tool to call out tokenism, and push for organisations to reach the highest appropriate rung that maximises the transfer of power.
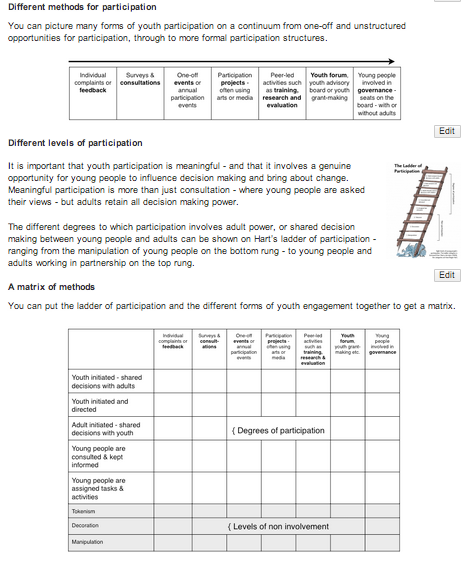
I’ve worked with various remixes of Arnstein’s ladder over the years, particularly building on building on Hart’s youth engagement remix) that draws attention to distinction between ‘participant initiated’ vs. ‘organisationally initiated’ decision making. In one remix we put forward with Bill Badham and the NYA Youth Participation Team we set the ladder against the range of methods of participations, and explored the need for any participation architecture to think about the pathways of participation through which individuals grow in their capacity to exercise power over decisions.
It would be great to see further developments of the Ada Lovelace framework consider the mix of participatory methods that are appropriate to certain data use contexts, and how these can be linked together. For example, informing all affected stakeholders about a data use project can be the first rung on the ladder towards a smaller number becoming co-designers, joint decision makers, or evaluators. And to design a meaningful consultation reaching a large proportion of affected stakeholders might require co-design or testing with a smaller group of diverse collaborators first: making sure that questions are framed and explained in legitimate and accessible ways.
Data collection, datasets, and data use
“Well-managed data can support organisations, researchers, governments and corporations to conduct lifesaving health research, reduce environmental harms and produce societal value for individuals and communities. But these benefits are often overshadowed by harms, as current practices in data collection, storage, sharing and use have led to high-profile misuses of personal data, data breaches and sharing scandals.”
It feels to me as though the report falls slightly (though, to be fair, not entirely) into the trap of seeing data as a pre-existing fixed resource, where the main questions to be discussed are who will access a dataset, on what terms and to what end. Yet, data is under constant construction, and in participatory data stewardship there should perhaps be a wider set of questions explicitly on the table such as:
Should this data exist at all?
How can this data be better collected in ways that respect stakeholders needs?
What data is missing that should be here? Are we considering the ‘lost opportunites’ as well as the risks of misuse?
Is this data structured in ways that properly represent the interests of all stakeholders?
Personally, I’m particularly interested in the governance role of data standards and structures, and exploring models to increase diverse participation in shaping these foundational parts of data infrastructure.
Decentering the dataset
The report argues that:
“There are currently few examples of participatory approaches to govern access and use of data…”
yet, I wonder if this comes from looking through a narrow lens for projects that are framed as just about the data. I’d hazard that there are numerous social change and public sector improvement projects have drawn upon data-sharing partnerships – albeit framed in terms of service or community change, rather than data-sharing per-se.
In both understanding existing practice, and thinking about the future of participatory data governance practices, I suspect we need to look at how questions about data use are embedded within wider questions about the kinds of change we are seeking to create. For example, if a project is planning to pool data from multiple organisations to identify ‘at risk families’ and to target interventions, a participatory process should take in both questions of data governance and intervention design – as to treat the data process in issolation of the wider use process makes for a less accessible, and potentially substantially biased, process.
Direct participation vs. representatives
One of the things the matrix of (youth) participation model tries to draw out is the distinction between participatory modalities based on ad-hoc individual involvement where stakeholders participate directly, through to those that involve sustained patterns of engagement, but that often move towards models of representative governance. Knowing whether you are aiming for direct or representative-driven participation is an important part of then answering the question ‘Who to involve?’, and being clear on the kind of structures needed to then support meaningful participation.
Where next?
It’s great to see participatory models of data governance on the agenda of groups like Ada Lovelace – although it also feels like there’s a way still to go to see many decades learning from the participation field better connecting with the kinds of technical decisions that affect so many lives.