Over the last 18 months we’ve worked with 66 fantastic authors, and many other contributors, reviewers and editorial board members, to pull together a review of the last decade of activity on open data. The resulting collection provides short essays that look at open data in different sectors, fromaccountability and anti-corruption, to the environment, land ownership and international aid, as well as touching on cross-cutting issues, differentstakeholder perspectives, and regional experiences. We’ve tried to distill key insights in overall and section introductions, and to draw out some emerging messages in an overall conclusion.
This has been my first experience pulling together a whole book, and I’m incredibly grateful to my co-editors, Steve Walker, Mor Rubinstein, and Fernando Perini, who have worked tirelessly over the project to bring together all these contributions, make sure the project is community driven, and to present a professional final book to the world, particularly in what has been a tricky year personally. The team at our co-publishers, African Mindsand IDRC (Simon, Leith, Francois and Nola) also deserve a great debt of thanks for their attention to detail and design.
I’ll ty and write up some reflections and learning points on the book process in the near future, and will be blogging more about specific elements of the research in the coming weeks, but for now, let me share the schedule of upcoming events in case any blog readers happen to be able to join. I’ll aim to update these with links to any outcomes from the sessions too later.
Roundtable at the Harvard Berkman Klein Center, with chapter authors David Eaves, Mariel Garcia Montes, Nagla Rizk, and response from Luminate’s Laura Bacon.
I’ll be connecting via hangouts to explore the connections between data literacy, artificial intelligence, and private sector engagement with open data
A panel discussion as part of the World Bank Let’s Talk Data series, exploring the development of open data over the last decade. This session will also be webcast – see detail in EventBrite.
We’ll be bringing together authors from lots of different chapters, including Shaida Baidee (National Statistics), Catherine Weaver (Development Assistance & Humanitarian Action), Jorge Florez (Anti-corruption), Alexander Howard (Journalists and the Media), Joel Gurin (Private Sector), Christopher Wilson (Civil Society) and Anders Pedersen (Extractives) to talk about their key findings in an informal world cafe style.
I’m joining Tariq Khokhar, Managing Director & Chief Data Scientist, Innovation, The Rockefeller Foundation, Adrienne Schmoeker, Deputy Chief Analytics Officer, City of New York and Beth Simone Noveck, Professor and Director, The GovLab, NYU Tandon (and also foreword writer for the book), to discuss changing approaches to data sharing, and how open data remains relevant.
[Summary: Over the next few months I’m working with Create Gloucestershire with a brief to catalyse a range of organisational data projects. Amongst these will be a hackathon of sorts, exploring how artists and analysts might collaborate to look at the cultural education sector locally. The body of this post shares some exploratory groundwork. This is a variation cross-posted from the Create Gloucestershire website.]
Create Gloucestershire have been exploring data for a while now, looking to understand what the ever-increasing volume of online forms, data systems and spreadsheets arts organisations encounter every day might mean for the local cultural sector. For my part, I’ve long worked with data-rich projects, focussing on topics from workers co-operatives and youth participation, to international aid and corruption in government contracting, but the cultural sector is a space I’ve not widely explored.
Often, the process of exploring data can feel like a journey into the technical: where data stands in opposition to all things creative. So, as I join CG for the next three months as a ‘digital catalyst’, working on the use of data within the organisation, I wanted to start by stepping back, and exploring the different places at which data, art and creativity meet with an exploratory blog post..
…and a local note on getting involved…
In a few weeks (late February 2019) we’ll be exploring these issues through a short early-evening workshop in Stroud: with a view to hosting a day-long data-&-art hackathon in late Spring. If you would like to find out more, drop me a line.
Post: Art meets data | Data meets art
For some, data and art are diametrically opposed. Data is about facts. Art about feelings.
Take a look at writings from the data visualisation community [1], and you will see some suggest that data art is just bad visualisation. Data visualisation, the argument runs, uses graphical presentation to communicate information concisely and clearly. Data art, by contrast, places beauty before functionality. Aesthetics before information.
Found on Flickr: “I’m not even sure what this chart says … but I think its gorgeous!” (Image CC-BY Carla Gates / Original image source: ZSL)
I prefer to see data, visualisation and art all as components of communication. Communication as the process of sharing information, knowledge and wisdom.
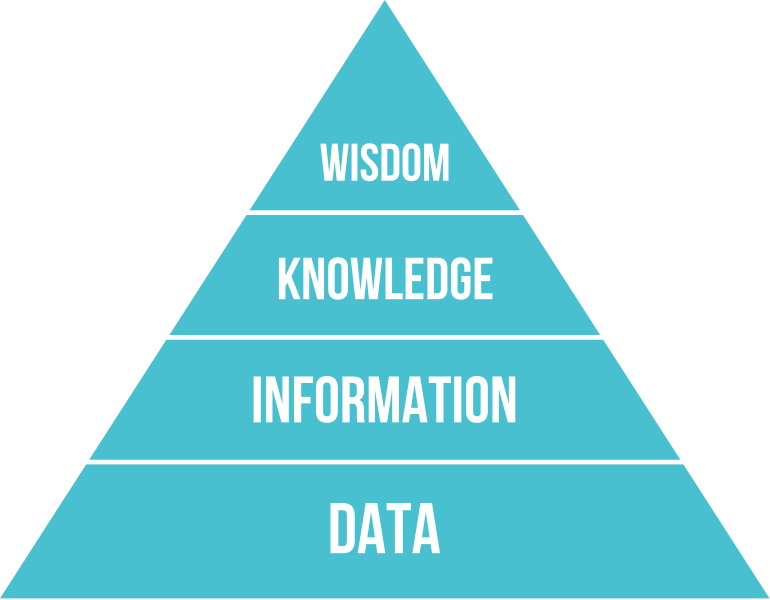
The DIKW pyramid proposes a relationship between Data, Information, Knowledge and Wisdom, in which information involves the representation of data into ‘knowing that’, whilst knowledge requires experience to ‘know how’, and wisdom requires perspective and trained judgement in order to ‘know why’. (Image CC BY-SA. Wikimedia Commons)
Turning data into information requires a process of organisation and contextualisation. For example, a collection of isolated facts may be made more informative when arranged into a table. That table may be made more easily intelligible when summarised through counts and averages. And it may communicate more clearly when visualisation is included.
An Information -> Data -> Information journey. GCSE Results in Arts Subjects. (Screenshots & own analysis)
But when seeking to communicate a message from the data, there is another contextualisation that matters: contextualising to the recipient: to what they already know, or what you may want to them to come to know. Here, the right tools may not only be those of analysis and visualisation, but also those of art: communicating a message shaped by the data, though not entirely composed of it.
Artistic expression could focus on a finding, or a claim from the data, or may seek to support a particular audience to explore, interrogate and draw interpretations from a dataset. (Image CC BY-SA Toby Oxborrow)
In our upcoming workshop, we’ll be taking a number of datasets about the state of cultural education in Gloucestershire, and asking what they tell us. We’ll be thinking about the different ways to make sense of the data, and the ways to communicate messages from it. My hope is that we will find different ways to express the same data, looking at the same topic from a range of different angles, and bringing in other data sources of our own. In that way, we’ll be able to learn together both about practical skills for working with data, and to explore the subjects the data represents.
In preparing for this workshop I’ve been looking at ways different practitioners have connected data and art, through a range of media, over recent years.
The Open Data Institute: Data as Culture
Since it’s inception, The Open Data Institute in London has run a programme called ‘Data as culture’, commissioning artists to respond to the increasing datification of society.
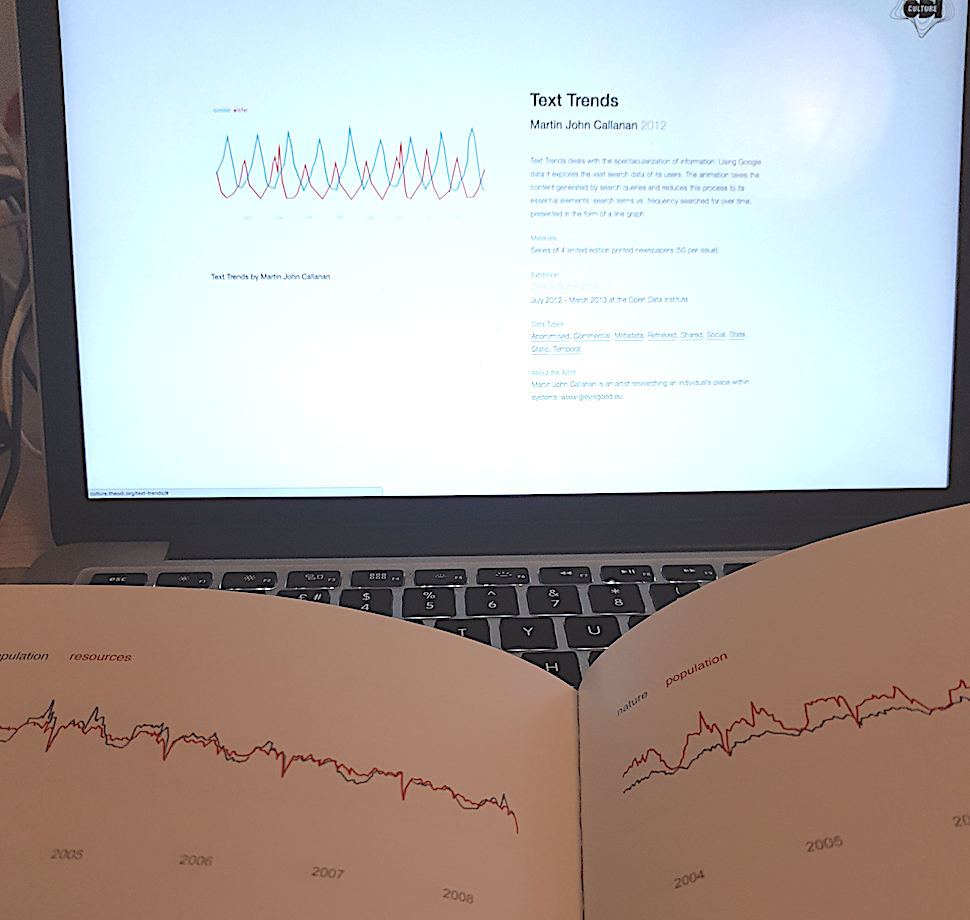
Some works take a relatively direct approach to representation, selecting particular streams of data from the web and using different media to represent them. Text trends, for example, selected and counterposes different google search trends on a simple graph over time. And the ODIs infamous vending machine provides free crisps in response to news media mentions of recession.
In representative works, the artist has chosen the signal to focus on, and the context in which it is presented. However, the underlying data remains more or less legible, and depending on the contextual media and the literacies of the ‘reader’, certain factual information can also be extracted from the artwork. Whilst it might be more time-consuming to read, the effort demanded by both the act of creation, and the act of reading, may invite a deeper engagement with the phenomena described by the data. London EC2 explores this idea of changing the message through changing the media: by woodblock printing twitter messages, thus slowing down the pace of social media, encouraging the viewer to rethink otherwise ephemeral information.
In other works that are directly driven by datasets, data is used more to convey an impression rather than to convey specific information. In the knitted Punchcard Economy banners, a representation working hours is combined with a pre-defined message resulting in data that can be read as texture, more than it can be read as pattern. In choosing how far to ‘arrange’ the data, the work finds its place on a spectrum between visualisation or aesthetic organisation.
Punchcard Economy, Sam Meech, 2013. ODI: 3.5 x 0.5m knitted banner, FutureEverything: 5 x 3m knitted banner & knitting machines.
Other works in the data as culture collection start not from datasets, but from artists responses to wider trends of datification. Works such as metography, flipped clock and horizon respond to forms of data and it’s presentation in the modern world, raising questions about data and representation – but not necessarily about the specific data which happens to form part of the work.
Other works still, look for the data within art, such as pixelquipu which takes it’s structure from pre-Columbian quipu (necklace-shaped, knotted threads from the Inca empire, that are thought to contain information relating to calendars and accounting in the empire). In these cases, turning information into data, and then representing it back in other way, is used to explore patterns that might not have otherwise been visible.
YoHa: Invisible Airs
Although it has also featured in the ODI’s Data as Culture collection, I want to draw out and look specifically at YoHa’s ‘Invisible Airs’ project. Not least because it was the first real work of ‘open data art’ I encountered, stumbling across it at an event in Bristol.
As newly released public spending records appear on screen, a pneumatically powered knife stabs a library book, sending a message about budget cuts, and inviting scrutiny of the data on screen.
It is a hard project to describe, but fortunately YoHa have a detailed project description and video on their website, showing the contraptions (participatory kinetic sculptures?) they created in 2014, driven by pneumatic tubes and actuated by information from Bristol City Council’s database of public spending.
In the video, Graham Harwood describes how their different creations (from a bike seat that rises up in response to spending transactions, to a pneumatic knife stabbing a book to highlight library service cuts) seek to ‘de-normalise’ data, not in the database designers sense of finding a suitable level of data abstraction, but in the sense of engaging the participant to understand otherwise dry data in new ways. The learning from the project is also instructive: in terms of exploring how far the works kept the attention of those engaging with them, or how far they were able to communicate only a conceptual point, before viewers attention fell away, and messages from the underlying data were lost.
Ultimately though, Invisible Airs (and other YoHa works engaging with the theme of data) are not so much communicating data, as communicating again about the role, and power, of data in our society. Their work seeks to bring databases, rather than the individual data items they contain, into view. As project commissioner Prof Jon Dovey puts it, “If you are interested in the way that power works, if you are interested in the way that local government works, if you are interested in the way that corporations work, if you are interested in the way that the state works, then data is at the heart of it…. The way your council tax gets calculated… the way your education budget gets calculated, all these things function through databases.”
Everyday data arts
Data as art need not involve costly commissions. For example, the media recently picked up on the story of a german commuter who had knitted a ‘train-delay scarf’, with choice of wool and colour representing length of delays. The act of creating was both a means to record, and to communicate, and in the process communicate much more effectively than the same data might have done if simply recorded in a spreadsheet, or even placed onto a chart with data visualisation.
‘Train Delay Scarf’ – a twitter sensation in January 2019.
Data sculpture and data-driven music
In a 2011 TED Talk, Nathalie Miebach has explored both how weather data can be turned into a work of art through sculpture and music, as well as questioning how the setting in which the resulting work is show affects how it is perceived.
She describes the creation of a vocabulary for turning the data into a creative work, but also the choice of a media that is not entirely controlled by the data, such that the resulting work is not entirely determined by the data, but also by its interaction with other environmental factors.
Dance your PhD, and dancing data
When reflecting on data and art, I was reminded of the annual Dance your PhD competition. Although the focus is more on expressing algorithms and research findings, than underlying datasets, it offers a useful way to reflect on ways to explain data, not only express what it contains.
In a similar vein, AlgoRythmics explain sorting algorithms using folk dance – a playful way of explaining what’s going on inside the machine when processing data.
There is an interesting distinction though between these two. Whilst Dance your PhD entries generally ‘annotate’ the dance with text to explain the phenomena that the dance engages with audience with, in AlgoRythmics, the dance itself is the entirety of the explanation.
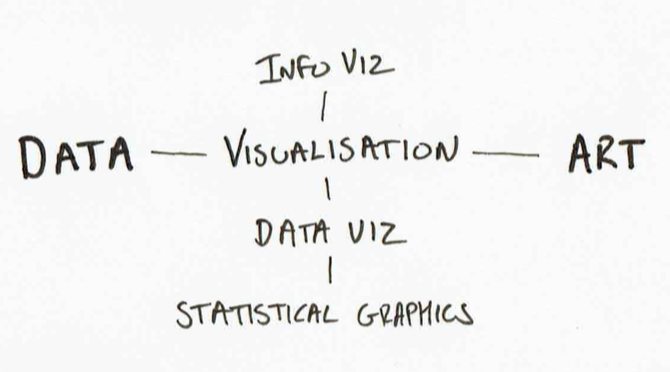
Visualisation
The fields of InfoViz and DataViz have exploded over the last decade. Blog such as InformationIsBeautiful,Flowing Data and Visualising Data provide a regular dose of new maps, charts and novel presentation of data. However, InfoViz and DataViz are not simply synonyms: they represent work that starts from different points of a Data/Information/Knowledge model, and with often different goals in mind.
Take, for example, David McCandless’ work in the ‘Information in Beautiful’ book (also presented in this TED Talk). The images, although often based on data, are not a direct visualisation of the data, but an editorialised story. The data has already been analysed to identify a message before it is presented through charts, maps and diagrams.
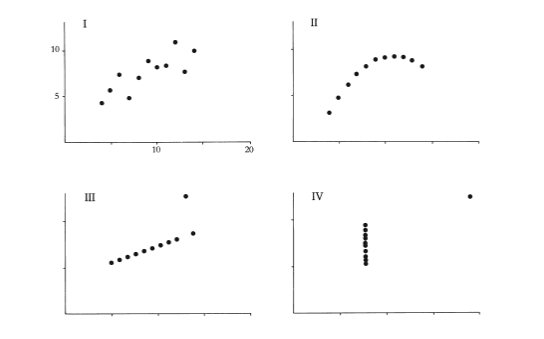
By contrast, in Edward Tufte’s work on data visualisation, or even statistical graphics, the role of visualisation is to present data in order to support the analytical process and the discovery of information. Tufte talks of ‘the thinking eye’, highlighting the way in which patterns that may be invisible when data is presented numerically, can become visible and intelligible when the right visual representation is chosen. However, for Tufte, the idea of the correct approach to visualisation is important: presenting data effectively is both an art and a technical skill, informed by insights and research from art and design, but fundamentally something that can be done right, or done wrong.
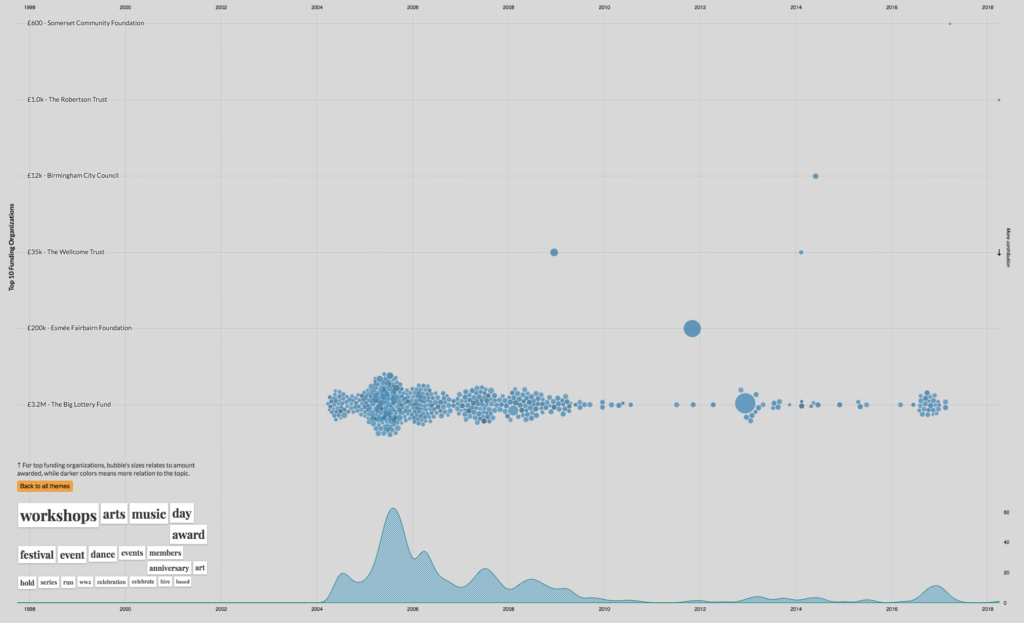
Other data visualisation falls somewhere between the extremes I’ve painted here. Exploratory data visualisations can seek to both support analysis, but also to tell a particular story through their selection of visualisation approach. A look at the winners of the recent 360 Giving Data Visualisation Challenge illustrates this well. Each of these visualisation draws on the same open dataset about grant making, but where ‘A drop in the bucket’ uses a playful animation to highlight the size of grants from different funders, Funding Themes extracts topics from the data and presents an interactive visualisation, inviting users to ‘drill down’ into the data and explore it in more depth. Others, like trend engine use more of a dashboard approach to present data, allowing the user to skim through and find, if not complete answers, at least refined questions that they may want to ask of the raw dataset.
Funding Trends for a ‘cluster’ of arts-related grants, drawing on 360 Giving data. Creator: Xavi Gimenez
Arts meet data | Data meet arts | Brokering introductions
Writing this post has given me a starting point to explore some data-art-dichotomies and to survey and link to a range of shared examples that might be useful for conversations in the coming weeks.
It’s also sparked some ideas for workshop methods we might be able to use to keep analytical, interpretative and communicative modes in mind when planning for a hackathon later this year. But that will have to wait for a future post…
Footnotes
[1]: I am overstating the argument in the blog post on art and data visualisation slightly for effect. The post, and comments in fact offer a nuanced dialogue worth exploring on the relationship of data visualisation and art, although still seeking to draw a clear disjunct relationship.
[Summary: I promise at some point this blog will carry content other than about incinerators and contracts. But, for the moment one more exciting instalment in the ongoing saga, in which we learn the contracting documents GCC have been fighting to hide show a 30% increase in Javelin Park costs.]
What’s just happened
Gloucestershire County Council (GCC) decided earlier this week to drop their appeal against an ICO ruling that they should release in full a 2015 ‘Value for Money’ analysis carried out just before they signed a revised contact with Urbaser Balfour Beatty (UBB) for building the Javelin Park Incinerator (which we’ve been referring to locally as the Ernst and Young report).
Throughout the process GCC have claimed that ‘commercial’ risk to both the Council and UBB prevents them from disclosing the documents. By dropping the appeal just a month before it was due to go to a Tribunal hearing, they avoid having to prove any of these claims in front of a panel and judge.
In addition, GCC appear to have delayed providing this information in order to commission Ernst and Young to produce another report, this time calculating an assumption-laden average gate fee, in order to continue to make the case for the project. This is at odds with the requirements of the Environmental Information Regulations to prompt disclosure – as presumably GCC must have known the commercial interest were no longer active prior to commissioning this new report, but instead chose to delay disclosure and spend taxpayers money on an ‘explanatory note’.
Where are we now
There’s a lot of history to this story, so to recap quickly.
Gloucestershire County Council have been seeking to build an Energy from Waste Incinerator for over a decade. In 2013 they signed a Public Private Partnership contract with UBB for the project. The contract was signed before planning permission was in place for the construction site. Planning was refused, leading to a two-year delay. This triggered a renegotiation of the contract in 2015, signed in January 2016. The plant is now under construction and close to being operational in 2019. Throughout the process GCC have claimed the project provides savings of up to £150m (later quietly reduced to £100m without explanation) over it’s 25 year life span.
Campaigners have long sought to see the contract, and in early 2016, the Information Rights Tribunal ruled that the majority of details, including gate fees (i.e. the price paid to burn waste) should be disclosed. I then requested a 2015 analysis relating to the re-negotiation, and was only given a highly redacted copy, not showing gate fees. I requested a review, and eventually appealed to the Information Commissioners Office (ICO) against authority refusal to release the information. The ICO ruled that the documents should be disclosed un-redacted. GCC appealed this decision in the summer, and since then have been preparing for a tribunal case claiming that disclosure would be against the contractors and the authorities commercial interest. They have now released the documents, although notably only claiming the contractor no longer has a commercial interest in them being confidential, leaving lingering questions about whether the authority had any legitimate commercial interest in non-disclosure all along.
What do we learn from the new documents
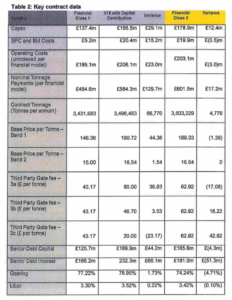
First below is the redacted document from GCC (click for full size). Then there is the equivalent table from the un-redacted and new report by Ernst and Young (which usefully does include the final rather than forecast figures for the renegotiated deal: i.e. the actual new contract numbers assuming there has been no further renegotiation since).
(Note that in the Table 2, the first ‘Variance’ column is between the originally signed contract, and the forecast revisions in 2015, and the second Variance column (in yellow) is between the forecast revisions, and the finally signed updated deal. So to get total variation from 2013 to 2016, you need to add these two columns together.)
So: what can we learn from the new data and documents:
(1) Firstly, the headline price per-tonne has increased by £42.97/tonne – a staggering 29.3% rise for a three year project delay (cumulative CPI inflation over the same period was 5.13%). The total per-tonne cost for the first 108,000 tonnes is now £189.33/tonne: far above anything any other authority in the country appears to be paying.
(2) This drives an increase in the nominal tonnage payments over the contract life of £446m to £601.5m. Whilst some of that might be offset by energy income/benefits, given these were also part of the case in 2013, this looks like a massive increase in costs – again just for a three year delay. (Given predicted waste volume rises in all the forecasts the contract is based on, a three year delay also involves starting the project when waste volumes are higher than in 2013 – so some change would be anticipated in this figure even if there was no gate fee increases. But the gate fee increases look like the major component turning Javelin Park from a £450m to a £600m project).
(3) Other tonnage payments have also increased – although the most notable change between the forecast, and signed renegotiation is that ‘Third Party Gate Fees’ have been kept down – suggesting that the financial modelling for the plant relies on attracting as much additional waste as possible at a low cost, with all the fixed costs of the project subsidised by the taxpayer.
(4) The Cabinet were told in November 2015 (E&Y VfM report; §3.1) that the capital costs of the project in UBB’s original Revised Project Plan “included a significantly inflated price of £177m.” but that “The council has had some success in negotiating this EPC price down and it now stands at £167m” and “the Council expects to see further improvements in this price”, yet by the signature of the new deal, the capital expenditure costs were also up 30% £178.9m – £2m higher than UBB’s opening gambit!
(5) The Value for Money calculations (E&Y VfM report, and restated in Table 3, new E&Y report) only carry out comparisons to ‘Termination (Landfill alternative)’ of which at least £60m is the cancellation cost signed up to in 2013. For this reason, the newly released Annex 1 of the report to Cabinet in 2015 (§6) explicitly acknowledges that the most that should be claimed in savings when this is taken out is £93m – and this is only when Council reserves are put into the project. It’s not clear why Cabinet Members continued to use a figure higher than this in public after this report.
(6) The first important thing from that last point are that at no point in 2015, did the Cabinet carry out a Value for Money assessment comparing the costs of continuing with the 30% more expensive contract, vs. cancelling and re-tendering. Instead, they pressed ahead with a closed-door renegotiation without competitive pressures – which goes a long way to explaining why the contractor could get such a big boost in costs.
(7) The second thing to note is that the claim of anything close to £100m savings is only secured by the cash injection into the project from reserves. Those are reserves that are then locked up and not available for other use. Without cash injections from reserves, the savings are much lower.
The mystery of the ‘Real Average Gate Fee’
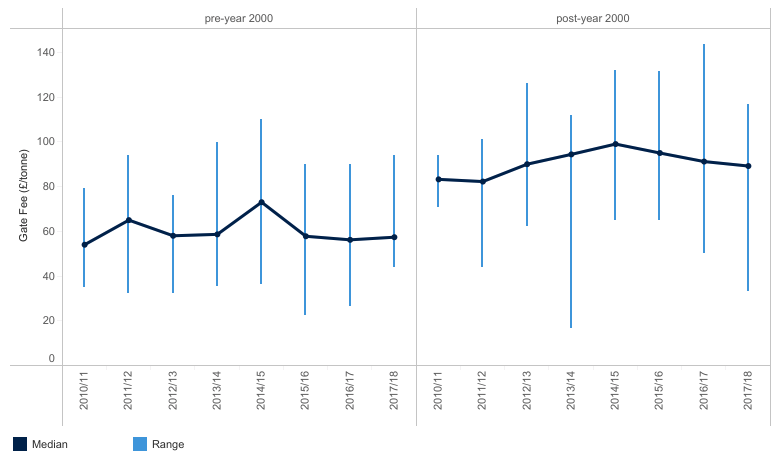
In the new Ernst and Young report that accompanies the response to my EIR/FOI request, a lot is made of a figure called the ‘Real Average Gate Fee’ (RAGF), which is calculated at £112.47/tonne.
Now – a few things about this number:
(1) I googled “Real Average Gate Fee” to see if this was based on an established industry wide methodology. As it turns out – the only place this phrase occurs on the whole of the Internet is in Ernst and Young’s report.
It turns out no-one apart from GCC know what a Real Average Gate Fee is either
(2) As I understand, this number is based on making best case assumptions about the income to the authority from electricity sales, and third-party income – and assuming the maximum contract tonnages set out in authority forecasts. If those assumptions are not met (e.g. we hit 60% recycling by 2020 and 70% by 2029/30; or waste volumes do not continue to rise as fast as forecast), then, because of the structure of the contract (all front-loaded costs on the first 108,000 tonnes; savings on waste volumes above this), the RAGF would very quickly rise. In other words, the RAGF is only valid if you accept high waste assumptions. In any other scenario it gets much higher.
(3) The report compares this to the range of real gate fees that WRAP found in their 2016 survey. Note that WRAP have a pretty robust methodology in their survey, and they state:
“Not all waste management services are costed or charged on a simple gate fee basis (£/tonne). In some cases a tonnage-related payment is just one element of a wider unitary charge paid by an authority” and that “every effort is made to eliminate such responses from the sample”
so the comparison of a constructed ‘Real Average Gate Fee’ from a unitary charge/PPP structure to a real gate fee is questionable at best.
(4) However, even more questionable is picking the 2016 data to compare the RAGF too. We now have 2017 data available from WRAP, and the E&Y report notes that this figure is based on the ‘Net Present Value based date of June 2015‘, so both 2015 and 2017 would seem more reasonable years to compare too.
Pro-tip: When looking to manipulate figures, always pick your comparison year to make your numbers look the best you can…
A quick look at WRAP’s EfW Overview dashboard for post-2000 plants gives us a clue as to why this year was chosen. 2016 is an outlier when it comes to maximum values in WRAPs survey. In 2015, the highest anyone responding to the survey was paying per tonne was £131/tonne, and in 2017 it was £116/tonne.
Even if we allow the not-really-comparable RAGF of £112/tonne – that put it right at the top of the range. Even a small reducting in income from energy, or reductions in waste, would push this into being the most expensive deal in the country.
If you compare the actual gate fee of £190/tonne for the first 108.000 tonnes, it is clear this is massively above what anyone else surveyed is paying.
What we still need to explore
The Ernst and Young Report VfM report notes that the overall lifetime project costs could have been substantially reduced with ‘Prudential Borrowing’ (i.e. relying on low interest loans the authority can achieve, rather than private banks). Annexe 1 to the 2015 Cabinet Report reveals this option was ignored, because it would have required discussion as part of the Council’s budget process in February 2016 and it states “the banks have advised that they need to achieve financial close by the end of the year [2015]”.
However, financial close was not achieved until January 2016 (it seems the banks didn’t mind so much after all?). It’s not yet clear to me what information Councillors outside cabinet had at the time on this decision – and what it tells us about the pursuit of a PFI option, when it appears other, much cheaper public funded options for the project were available.
There is also a question of the missing OJEU (Official Journal of the European Union) notice. It seems that, whilst in most cases, any contract variation of over 10% in value after the Public Contract Regulations 2015 came into force should normally have involved re-tendering, an exception may have been permissable for this project because of ‘unforseen circumstances’ (although whether the planning refusal is something a dilligent authority could not have forseen is open to major question). Notwithstanding that – LGA guidance states that in a case of major contract modification “a special type of notice must be published in OJEU” a “‘Notice of modification of a contract during its term’.”
I’ve not been able to find any evidence that such a notice was issued, and Cllr Rachel Smith has also asked for copies of all OJEU notices related to the project a number of times, and a contract modification notice has never been amongst them.
Where next?
Hopefully a Christmas break! Whilst it was kind of GCC to drop these documents just before Christmas – I’m hoping to have at least a bit of time off.
However, far from proving the value for money or transparency of the project as Councillors claim: these documents show there are still major questions to be answered about how a secret renegotiation led to 30% increase in costs, and why no assessments took place to look at non-landfill alternatives and create at least some sort of competitive pressure at the time of renegotiation.
There are also major questions to be asked about the handing of the Information Tribunal appeal. But those can wait for a day or two at least.
In a few weeks time (October 12th) I’m going to be leaving Open Data Services Co-op and starting a short career-break of sorts: returning to my research roots, spending some time exploring possible areas of future focus, and generally taking a bit of time out.
I’ll be leaving projects in capable hands, with colleagues at Open Data Services continuing to work on Open Contracting, Beneficial Ownership, 360 Giving, Org-id.guideIATI and Social Economy data standards projects. One of the great advantages of the worker co-operative model we’ve been developing over the last three and a half years is that, instead of now needing to seek new leaders for the technical work on these projects, we’ve been developing shared leadership of these projects from day one.
I first got involved in the development of open data standards out of research interest: curious about how these elements of data infrastructure were created and maintained, and about the politics embedded within, or expressed through, them. Over the last five years my work has increasingly focussed on supporting open data standard adoption, generating tons of learning – but with little time to process it or write it up. So – at least for a while – I’ll be stepping back from day-to-day work on specific standards and data infrastructure, and hopefully next year will find ways to distill the last few years learning in some useful form.
Between now and the end of 2018, I’ll be working on editing the State of Open Data collection of essays for the OD4D network. Then in early 2019, I’m planning for a bit of time off completely, before starting to explore new projects from April onwards.
I’m imensely proud of what we’ve done with Open Data Services Co-op over the last 3.5 years, and grateful to colleague for co-creating something that both supports world-changing data projects, but that also supports team members in their own journeys. If you ever need support with an open data project, do not hesitate to drop them a line.
[Summary: The Information Commissioner’s Office has upheld an appeal against continued redaction of key financial information about the Javelin Park Incinerator Public Private Partnership (PPP) project in Gloucestershire]
The Story So Far
I’ve written before about controversy over the contract for Javelin Park, a waste incinerator project worth at least £0.5bn and being constructed just outside Stroud as part of a 25-year Public Private Partnership deal. There’s a short history at the bottom of this article, which breaks off in 2015 when the Information Commissioners’ Office last ruled against Gloucestershire County Council (GCC) and told them to release an unredacted copy of the PPP contract. GCC appealed that decision, but were finally told by the Information Tribunal in 2017 to publish the contract: which they did. Sort of. Because in the papers released, we found out about a 2015 renegotiation that had taken place, meaning that we still don’t know how much local taxpayers are on the hook for, nor how the charging model affects potential recycling rates, or incentives to burn plastics.
Tomorrow we’ll be heading to Gloucester in support of Sid’s continued campaign for information, and for action to bring accountability to this mega-project.
It’s against this backdrop that I wanted to draw out some of the key elements of the ICO’s decision notice, and observations on GCC responses to FOI and EIR requests.
It is notable that every request for information relating to Javelin Park has been met with very delayed replies, exceeding the statutory limits set down in the Freedom of Information Act (FOIA), and the stricter Environmental Information Regulations (EIR).
The decision notice states that the “council failed to comply with the requirements of Regulation 5(2) and Regulation 14(2)” which set strict time limits on the provision of information, and the grounds for which an authority can take extra time to respond.
Yet, we’re seeing in the latest requests, that GCC suggest that they will need until the end of June (which falls, curiously, just days after the next full meeting of the County Council) to work out what they can release. I suspect consistent breaches of the regulations on timeliness are not likely to be looked on favourably by the ICO in any future appeals.
The information tribunal principles stand
The Commissioners decision notice draws heavily on the earlier Information Tribunal ruling that noted that, whilst there are commercial interests of the Authority, and UBB at play, there are significant public interests in transparency, and:
“In the end it is the electorate which must hold the Council as a whole to account and the electorate are more able to do that properly if relevant information is available to all”
The decision note makes clear that the reasoning applies to revisions to the contract:
Even with the disclosures ordered by the Tribunal from the contract the Commissioner considers that it is impossible for the public to be fully aware of the overall value for money of the project in the long term if it is unable to analyse the full figures regarding costs and price estimates which the council was working from at the time of the revised project plan.
going on to say:
The report therefore provides more current, relevant figures which the council used to evaluate and inform its decisions regarding the contract and it will presumably be used as a basis for its future negotiations over pricing and costs. Currently these figures are not publicly available, and therefore the public as a whole cannot create an overall picture as to whether the EfW development provides value for money under the revised agreement.
As the World Bank PPP Disclosure Framework makes clear, amendment and revisions to a contract are as important as the contract itself, and should be proactively published. Not laboriously dragged out of an authority through repeated trips to information tribunals.
Prices come from markets, not from secrets
A consistent theme in the GCCs case for keeping heavy redactions in the contract is that disclosure of information might affect the price they get for selling electricity generated at the plant. However, the decision notice puts the point succinctly:
Whilst she [the Commissioner] also accepts that if these figures are published third parties might take account of them during negotiations, the main issue will be the market value of electricity at the time that negotiations are taking place.
As I recall from first year economics lectures (or perhaps even GCSE business studies…): markets function better with more perfect information. The energy market is competitive, and there is no reason to think that selective secrecy will distort the market or secure the authority a better deal.
The ICO decision notice is nuanced. It does find some areas where, with the commercial interest of the private party invoked, public interest is not strong enough to lead to disclosure. The Commissioner states:
These include issues such as interest and debt rates and operating costs of UBB which do not directly affect the overall value for money to the public, but which are commercially sensitive to UBB.
This makes some sense. As this decision notice relates to a consultants report on Value for Money, rather than the contract with the public authority, it is possible for there to be figures that do not warrant wider disclosure. However, following the precedent set by the Information Tribunal, the same reasoning would only apply to parts of a contract if they had been agreed in advance to be commercially confidential. As Judge Shanks found, only a limited part of the agreement between UBB and GCC was covered by such terms. Any redactions GCC now want to apply to a revised agreement should start only from consulting contract Schedule 23 on agreed commercial confidential information.
Where next?
GCC have either 28 days to appeal the decision notice, or 35 days to provide the requested information. The document in question is only a 29 page report, with a small number of redactions to remove, so it certainly should not take that long.
Last time GCC appealed to a Tribunal in the case of the 2013 Javelin Park Contract they spent upwards of £400,000 of taxpayers money on lawyers*, only to be told to release the majority of the text. Given the ICO Decision Notice makes clear it is relying on the reasoning of the Tribunal, a new appeal to the tribunal would seem unlikely to succeed.
However, we do now have to wait and see what GCC do, and whether we’ll get to know what the renegotiated contract prices were in 2015. Of course, this doesn’t tell us whether or not there has been further renegotiation, and for that we have to continue to push for proactive transparency and a clear open contracting policy at GCC that will make transparency the norm, rather than something committed local citizens have to fight for through self-sacrificing direct action.
*Based on public spending data payments from Residential Waste Project to Eversheds.
[Summary: Preliminary notes on open data, privacy and AI]
At the heart of open data is the idea that when information is provided in a structured form, freely accessible, and with permission granted for anyone to re-use it, latent social and economic value within it can be unlocked.
Privacy positions assert the right of individuals to control their information and data, and data about them, and to have protection from harms that might occur through exploitation of their data.
Artificial intelligence is a field of computing concerned with equipping machines with the ability to perform tasks that many previously have required human intelligence, including recognising patterns, making judgements, and extracting and analysing semi-structured information.
Around each of these concepts vibrant (and broad based) communities exist: advocating respectively for policy to focus on openness, privacy and the transformative use of AI. At first glance, there seem to be some tensions here: openness may be cast as the opposite of privacy; or the control sought in privacy as starving artificial intelligence models of the data they could use for social good. The possibility within AI of extracting signals from messy records might appear to negate the need to construct structured public data, and as data-hungry AI draws increasingly upon proprietary data sources, the openness of data on which decisions are made may be undermined. At some points these tensions are real. But if we dig beneath surface level oppositions, we may find arguments that unite progressive segments of each distinct community – and that can add up to a more coherent contemporary narrative around data in society.
This was the focus of a panel I took part in at RightsCon in Toronto last week, curated by Laura Bacon of Omidyar Network, and discussing with Carlos Affonso Souza (ITS Rio) and Frederike Kaltheuner (Privacy International) – and the first in a series of panels due to take place over this year at a number of events. In this post I’ll reflect on five themes that emerged both from our panel discussion, and more widely from discussions I had at RightsCon. These remarks are early fragments, rather than complete notes, and I’m hoping that a number may be unpacked further in the upcoming panels.
The historic connection of open data and AI
The current ‘age of artificial intelligence’ is only the latest in a series of waves of attention the concept has had over the years. In this wave, the emphasis is firmly upon the analysis of large collections of data, predominantly proprietary data flows. But it is notable that a key thread in advocacy for open government data in the late 2000s came from Artificial Intelligence and semantic web researchers such as Prof. Nigel Shadbolt, whose Advanced Knowledge Technologies (AKT) programme was involved in many early re-use projects with UK public data, and Prof. Jim Hendler at TWC. Whilst I’m not aware of any empirical work that explores the extent to which open government data has gone on to feed into machine-learning models, in terms of bootstrapping data-hungry research, there is a connection here to be explored.
There also an argument to be made that open data advocacy, implementation and experiences over the last ten years have played an important role in contributing to growing public understandings of data, and in embedding cultural norms around seeking access to the raw data underlying decisions. Without the last decade of action on open data, we might be encountering public sector AI based purely on proprietary models, as opposed to now navigating a mixed ecology of public and private AI.
(Some) open data is getting personal
Its not uncommon to hear open data advocates state that open data only covers ‘non-personal data’. It’s certainly true that many of the datasets sought through open data policy, such as bus timetables, school rankings, national maps, weather reports and farming statistics don’t contain an personally identifying information (PII). Yet, whilst we should be able to mark a sizable teritory of the open data landscape as free from privacy concerns, there are increasingly blurred lines at points where ‘public data’ is also ‘personal data’.
In some cases, this may be due to mosaic effects: where the combination of multiple open datasets could be personally identifying. In other cases, the power to AI to extract structured data from public records about people raises interesting questions about how far permissive regimes of access and re-use around those documents should also apply to datasets derived from them. However, there are also cases where open data strategies are being applied to the creation of new datasets that directly contain personally identifying information.
In the RightsCon panel I gave the example of Beneficial Ownership data: information about the ultimate owners of companies that can be used to detect ilicit use of shell companies for money laundering or tax evasion, or that can support better due dilligence on supply chains. Transparency campaigners have called for beneficial ownership registers to be public and available as open data, citing the risk that restricted registers will be underused and will much less effective than open registers, and drawing on the idea of a social contract that means the limited liability conferred by a company comes with the responsibility to be identified as party to that company. We end up then with data that is both public (part of the public record), but also personal (containing information about identified individuals).
Privacy is not secrecy: but consent remains key
Frederike Kaltheuner kicked off our discussions of privacy on the panel by reminding us that privacy and secrecy are not the same thing. Rather, privacy is related to control: and the ability of individuals and communities to excercise rights over the presentation and use of their data. The beneficial ownership example highlights that not all personal data can or should be kept secret, as taking an ownership role in a company comes with a consequent publicity requirement. However, as Ann Cavoukian forcefully put the point in our discussions, the principle of consent remains vitally important. Individuals need to be informed enough about when and how their personal information may be shared in order to make an informed choice about entering into any relationship which requests or requires information disclosure.
When we reject a framing of privacy as secrecy, and engage with ideas of active consent, we can see, as the GDPR does, that privacy is not a binary choice, but instead involves a set of choices in granting permissions for data use and re-use. Where, as in the case of company ownership, the choice is effectively between being named in the public record vs. not taking on company ownership, it is important for us to think more widely about the factors that might make that choice trickier for some individuals or groups. For example, as Kendra Albert expained to me, for trans-people a business process that requires current and former names to be on the public record may have substantial social consequences. This highlights the need for careful thinking about data infrastructures that involve personal data, such that they can best balance social benefits and individual rights, giving a key place to mechanisms of acvice consent: and avoiding the creation of circumstances in which individuals may find themselves choosing uncomfortably between ‘the lesser of two harms’.
Is all data relational?
One of the most challenging aspects of the receny Cambridge Analytica scandal is the fact that even if individuals did not consent at any point to the use of their data by Facebook apps, there is a chance they were profiled as a result of data shared by people in their wider network. Whereas it might be relatively easy to identify the subject of a photo, and to give that individual rights of control over the use and distribution of their image, an individual ownership and rights framework is difficult can be difficult to apply to many modern datasets. Much of the data of value to AI analysis, for example, concerns the relationship between individuals, or between individuals and the state. When there are multiple parties to a dataset, each with legitimate interests in the collection and use of the data, who holds the rights to govern its re-use?
Strategies of regulation
What unites the progressive parts of the open data, privacy and AI communities? I’d argue that each has a clear recognition of the power of data, and a concern with minimising harm (albeit with a primary focus in individual harm in privacy contexts, and with the emphasis placed on wider social harms from corruption or poor service delivery by open data communities)*. As Martin Tisné has suggested, in a context where harmful abuses of data power are all around us, this common ground is worth building on. But in charting a way forward, we need to more fully unpack where there are differences of emphasis, and different preferences for regulatory strategies – produced in part by the different professional backgrounds of those playing leadership roles in each community.
(*I was going to add ‘scepticism about centralised power’ (of companies and states) to the list of common attributes across progressive privacy, open data and AI communities, but I don’t have a strong enough sense of whether this could apply in an AI context.)
In our RightsCon panel I jotted down and shared five distinct strategies that may be invoked:
Reshaping inputs – for example, where an AI system is generated biased outputs, work can take place to make sure the inputs it recieves are more representative. This strategy essentially responds to negative outcomes from data by adding more, corrective, data.
Regulating ownership – for example, asserting that individuals have ownership of their data, and can use ownership rights to make claims of control over that data. Ownership plays an important role in open data licensing arrangements, but runs up against the ‘relational data problem’ in many cases, where its not clear who has ownership rights.
Regulating access – for example, creating a dataset of company ownership only available to approved actors, or keeping potentially disclosive AI training datasets from being released.
Regulating use – for example, allowing that a beneficial ownership register is public, but ensuring that uses of the data to target individuals is strictly prohibited, and prohibitions are enforced.
Remediating consequences – for example, recognising that harm is caused to some groups by the publicity of certain data, but judging that the net public benefit is such that the data should remain public, but the harm should be redressed by some other aspect of policy.
By digging deeper into questions of motivations, goals and strategies my sense is we will better be able to find the points where AI, privacy and open data intersect in a joint critical engagement with todays data environment.
[Summary: Thinking aloud about open data and data standards as governance tools]
There are interesting shifts in the narratives of open data taking place right now.
Earlier this year, the Open Data Charter launched their new stategy: “Publishing with purpose”, situating it as a move on from the ‘raw data now’ days where governments have taken an open data initaitive to mean just publishing easy-to-open datasets online, and linking to them from data catalogues.
The Open Contracting Partnership, which has encouraged governments to purposely prioritise publication of procurement data for a number of years now, has increasingly been exploring questions of how to design interventions so that they can most effectively move from publication to use. The idea enters here that we should be spending more time with governments focussing on their use cases for data disclosure.
The shifts are welcome: and move closer to understanding open data as strategy. However, there are also risks at play, and we need to take a critical look at the way these approaches could or should play out.
In this post, I introduce a few initial thoughts, though recognising these are as yet underdeveloped. This post is heavily influenced by a recent conversation convened by Alan Hudson of Global Integrity at the OpenGovHub, where we looked at the interaction of ‘(governance) measurement, data, standards, use and impact ‘.
(1) Whose purpose?
The call for ‘raw data now‘ was not without purpose: but it was about the purpose of particular groups of actors: not least semantic web reseachers looking for a large corpus of data to test their methods on. This call configured open data towards the needs and preferences of a particular set of (technical) actors, based on the theory that they would then act as intermediaries, creating a range of products and platforms that would serve the purpose of other groups. That theory hasn’t delivered in practice, with lots of datasets languishing unused, and governments puzzled as to why the promised flowering of re-use has not occurred.
Sunlight Foundation recently published a write-up of their engagement with Glendale, Arizona on open data for public procurement. They describe a process that started with a purpose (“get better bids on contract opportunities”), and then engaged with vendors to discuss and test out datasets that were useful to them. The resulting recommendations emphasise particular data elements that could be prioritised by the city administration.
Would Glendale have the same list of required fields if they had started asking citizens about better contract delivery? Or if they had worked with government officials to explore the problems they face when identifying how well a vendor will deliver? For example, the Glendale report doesn’t mention including supplier information and identifiers: central to many contract analysis or anti-corruption use cases.
If we see ‘data as infrastructure’, then we need to consider the appropriate design methods for user engagement. My general sense is that we’re currently applying user centred design methods that were developed to deliver consumer products to questions of public infrastructure: and that this has some risks. Infrastructures differ from applications in their iterability, durability, embeddedness and reach. Premature optimisation for particular data users needs may make it much harder to reach the needs of other users in future.
I also have the concern (though, I should note, not in any way based on the Glendale case) that user-centred design done badly, can be worse than user-centred design done not at all. User engagement and research is a profession with it’s own deep skill set, just as work on technical architecture is, even if it looks at first glance easier to pick up and replicate. Learning from the successes, and failures, of integrating user-centred design approaches into bureacratic contexts and government incentives structures need to be taken seriously. A lot of this is about mapping the moments and mechanisms for user engagement (and remembering that whilst it might help the design process to talk ‘user’ rather than ‘citizen’, sometimes decisions of purpose should be made at the level of the citizenry, not their user stand-ins).
(3) International standards, local adoption
(Open) data standards are a tool for data infrastructure building. They can represent a wide range of user needs to a data publisher, embedding requirement distilled from broad research, and can support interoperabiliy of data between publishers – unlocking cross-cutting use-cases and creating the economic conditions for a marketplace of solutions that build on data. (They can, of course, also do none of these things: acting as interventions to configure data to the needs of a particular small user group).
But in seeking to be generally usable, standard are generally not tailored to particular combinations of local capacity and need. (This pairing is important: if resource and capacity were no object, and each of the requirements of a standard were relevant to at least one user need, then there would be a case to just implement the complete standard. This resource unconstrained world is not one we often find ourselves in.)
How then do we secure the benefits of standards whilst adopting a sequenced publication of data given the resources available in a given context? This isn’t a solved problem: but in the mix are issues of measurement, indicators and incentive structures, as well as designing some degree of implementation levels and flexibility into standards themselves. Validation tools, guidance and templated processes all help too in helping make sure data can deliver both the direct outcomes that might motivate an implementer, whilst not cutting off indirect or alternative outcomes that have wider social value.
(I’m aware that I write this from a position of influence over a number of different data standards. So I have to also introspect on whether I’m just optimising for my own interests in placing the focus on standard design. I’m certainly concerned with the need to develop a clearer articulation of the interaction of policy and technical artefacts in this element of standard setting and implementation, in order to invite both more critique, and more creative problem solving, from a wider community. This somewhat densely written blog post clearly does not get there yet.)
Some preliminary conclusions
In thinking about open data as strategy, we can’t set rules for the relative influence that ‘global’ or ‘local’ factors should have in any decision making. However, the following propositions might act as starting point for decision making at different stages of an open data intervention:
Purpose should govern the choice of dataset to focus on
Standards should be the primary guide to the design of the datasets
User engagement should influence engagement activities ‘on top of’ published data to secure prioritised outcomes
New user needs should feed into standard extension and development
User engagement should shape the initiatives built on top of data
Some open questions
Are there existing theoretical frameworks that could help make more sense of this space?
Which metaphors and stories could make this more tangible?
[Summary: Looking for great candidates to drive progress on Open Government in the UK through the UK Civil Society OGP Steering Committee and Multi-stakeholder Forum. Nomination deadline: 16th April]
Nominations are now open for civil society members of the UK Open Government Partnership (OGP) Multi-stakeholder Forum. It’s a key time for open government in the UK, as we look to maintain momentum and push forward new reforms, within a wider national and global environment where open, participatory and effective governance is increasingly under threat.
Yesterday, members of the current Civil Society Network Steering Committee and other guests were hosted at the Speakers House in Parliament to hear an update from Dr Ben Worthy, the independent reviewer of UK progress. The event underscored the importance of active civil society engagement to put issues on the open government agenda, and the unique opportunity offered by the OGP process to accelerate reforms and support deep dialogue between government and civil society. Ben also challenged those assembled to think about the ‘signature reforms’, engagement experiments and high profile interventions that the next National Action Plan should support, and to look to engage more with Parliament to secure parliamentary scrutiny of transparency and open government policy.
.@opengovuk#ogpIRM The speaker emphasising importance of OGP work on transparency and accountability. Closing words on the need to focus on impacts of open gov for the poorest and most vulnerable in society: open gov for all. pic.twitter.com/YvKTJiTfoc
One of the ways in the UK OGP Civil Society Network we’ve been preparing to meet these challenges is by updating the Terms of Reference for the Civil Society Network Steering Group so that it is ready to act as the civil society half of a standing Multi-stakeholder Forum on Open Government in the UK. This will meet regularly with government, including with Ministers with Open Government responsibility, to secure and monitor open government commitments.
To bring on board a wider set of skills and experience, we’ve also increased the number of places on the Steering Committee, creating five spaces now up for election through an open process that also seeks to secure a good gender balance, and representation of both civil society organisations and independent citizens. I’m personally keen to see us use this opportunity to bring new skills and experience onboard for the Steering Committee and Multi-stakeholder Forum, including people with experience of working on reforms within government (though current government officials working on open gov policy are not eligible to apply), specialists in civic participation, and experts on right to information issues.
Responsibilities of Steering Group members include:
Engaging with the relevant Minister and civil servants with responsibility for the OGP
Participating in the Multistakeholder Forum between government and civil society
Speaking on behalf of the Open Government Network
Supporting and overseeing the work of the Network Coordinator and ensuring the smooth running of the OGN
and to date it’s been a committment of 3 – 15 hours a month (depending on the stage of the National Action Plan process) with a regular Steering Committee call and periodic meetings (usually in London, though we’ve been trying to move around the country whenever possible) with government officials and other members of the civil society network. The nomination form is here if you are interested – and even if you’re not interested in a role on the Steering Committee right now, do join the network via it’s open mailing list for other opportunities to get involved.
As a current Steering Committee member, I’d be happy to answer any questions (@timdavies) about the process and the potential here to take forward open government reforms in the UK, and as part of the 70+ country strong global OGP network.
[Summary: reflections and ideas building on conversations at the OGP National Action Plan workshop in Bristol yesterday with ideas about a fund for scoping studies, strengthening the ICO role around contract disclosure, and better national Management Information (and a continuation of this blog’s ‘Open Contracting’ season: I promise I’ll write about some other things soon!]
*The UK government endorses the principles of open contracting. We will build on the existing foundation of transparency in procurement and contracting and, in consultation with civil society organisations and other stakeholders, we will look at ways to enhance the scope, breadth and usability of published contractual data. *
In 2016, the Open Contracting moved up to slot number 5, with a commitment to:
…implement the Open Contracting Data Standard (OCDS) in the Crown Commercial Service’s operations by October 2016; [and to] begin applying this approach to major infrastructure projects, starting with High Speed Two, and rolling out OCDS across government thereafter.
As we head towards the next National Action Plan in 2018, it’s time to focus on local implementation. Whilst government policies on procurement, and even on asset disposals (e.g. selling off government land), provide clear guidance on transparency and publication of data and documents (including full contract text), local implementation is sorely lacking.
The day after Carillion’s collapse it was only possible to locate less than 30 of the 400+ government contracts with Carillion through the national Contracts Finder dataset. And none had the text of contracts attached. Local authorities continue to invoke ‘commercial confidentiality’ as a blanket reason to keep procurement or asset sale information secret, increasing corruption risks, and undermining opportunities to promote value for money, local economic development and strategic procurement across the public sector.
When policy is good, but implementation is poor, what levers are there? At the recent Bristol workshop we explored a range of opportunities. In general, approaches fall into a few different categories:
Improving enforcement. There are few consequences right now for a government agency that is not following procurement guidance. Although local government is prone to resist new or strengthened requirements that come without funding, there may be opportunities to strengthen regulators, or increase the consequences of non-compliance. However, this often needs to rely on:
Better monitoring. It’s only when we can see which authorities are failing in their procurement transparency obligations, or when we can identify leading and lagging agencies when it comes to use of pre-procurement dialogues for public and supplier engagement, that targeted enforcement of key practices becomes possible. Monitoring alone can sometimes create incentives for improved practice.
Making it easier. Confusion over the meaning of commercial confidentiality may be preventing good practice. Guidance from government, or better design of software tools, can all help streamline the process of complying. Government may have a role in setting the standards for procurement software, as well as the data standards for publishing transparency procurement information.
Show the benefits. The irony of low compliance with procurement best practices on transparency is, well, that best practice is often better. It brings savings, and better services. A programme to demonstrate this has a lot of value.
So, what could this look like in terms of concrete commitments:
Scoping study support fund. Open Contracting has the potential to be win-win-win: efficiency for government, accountability to citizens, and opportunities for local businesses. But building multi-stakeholder support for new initiatives, and setting priorities for local action needs an understanding of the the current situation. Where are the biggest blocks to opening up information on procurement? Are the challenges policy or process? Where will leadership for change come from? How can different stakeholders work together to generate, share and use data and information – and to design better procurement processes? These are all questions that can be answered through a scoping study.
Development Gateway, HIVOS and the Open Contracting Partnership have well-tested scoping study methods that have been used around the world to support national-level Open Contracting initiatives. Adapting this method for city or regional use, and providing kick-start funding to help local partnerships come together, assess their situation, and plan for change, could be a very effective way to catalyse a move from open contracting policy to local, relevant and high-impact practice.
With just £100k investment, Central government could support studies in 10 or more areas.
Improved national metrics. As part of implementation of the last NAP commitment, the Contracts Finder platform now has a (very) basic statistics page, providing an overview of which public authorities are publishing their contracts. With the underlying open data, it’s possible to compute a few more metrics, exploring the kind of contracts different agencies are publishing information on, or assessing gaps between tender and award. However, central government could go a lot further in providing Business Intelligence dashboards on top of the data in Contracts Finder, and publishing much more accessible reports on policy compliance. The OpenTender.eu project demonstrate some of what can be done with the analysis of collated procurement data, calculating a range of indicators.
Empowering the Information Commissioner’s Office. The ICO has a key role in enforcing the public right to information, yet has a substantial backlog of cases, many including FOI requests relating to contracts. Support for the ICO to develop further guidance, monitor compliance and take enforcement activities against authorities who are hiding behind bogus commercial confidentiality arguments, could shift the balance from the current ‘closed by default’ position when it comes to the contract details that matter, to proper implementation of the open-by-default policy.
Extending FOI for contractors. Although the idea that the Freedom of Information Act should apply to any provider of public services, regardless of whether they are public of private sector, is one that has been put forward, and knocked back, in previous National Action Planning processes, it remains as relevant as ever. In light of the recent Carillion Collapse, and with outsourcing arrangements looking increasingly shaky, the public right to know about delivery of public services clearly needs re-asserting more strongly.
Improved model contract clauses. Earlier rounds of the OGP NAP have secured model contract clauses for national government contracts, focussing on provision of performance information. Revisiting the question of model clauses, but with a focus on local government, and on further requirements around transparency of delivery, would offer a parallel route to increase transparency of local service delivery, creating a contractual right to information, pursued alongside efforts to extend the legal right through FOI.
A mix of the commitments above would combine different levers: enforcement, incentives and oversight – with a chance to truly build effective open contracting. Within the wider UK landscape, for the OGP process to remain credible, we will need to see some serious and ambitious commitments, and open contracting is a key area where these could be made.
(Hat-tip to @carla_denyer for the framing of how to motivate government action used in the above, and to all at the Bristol @openGovUK workshop who discussed Open Contracting.)
The legislative requirement to publish most opportunities and awards over £10,000 via the Contracts Finder platform;
The policy committment of central government to see all tender documents, and contract texts attached to those notices on Contracts Finder;
Guidance on all the documents that go to make up the contract (and so that should be attached to Contracts Finder)
Re-iteration of the limitations to redaction of contract documents;
Recommendations on transparency clauses to include in new contracts, to have clear agreement with suppliers over information that will be public.
As contracting transparency policy goes: this is good stuff. We’re not yet at the stage in the UK of having the kind of integrated public financial management systems that give us transparency from planning to final payment, nor are their the kind of lock-in measures such as checking a contract has been published before any invoices against it are paid. But it does provide a clear foundation to build on.
The platform that backs up this policy, Contracts Finder, has also seen some good progress recently. With hundreds of tender and award notices posted every week, it continues to provide good structured data in the Open Contracting Data Standard through an open API. In the last few weeks, the data has also started to capture company registration numbers for suppliers – a really important key to linking up contracting and company ownership information, and to better understanding patterns of public sector contracting. The steady progress of Contracts Finder as a national platform (with a number of features also now added to help capture sub-contracting processes too) makes it absolutely key to monitoring and improving implementation of the policies described above.
There are still some challenges for the platform: data quality (and document availability) for many of the records in Contracts Finder relies upon the features of e-Procurement systems used by departments or local authorities to manage their contracting processes. If these systems don’t encourage inclusion of company identifiers, or contracting documents, we may struggle to reach full policy compliance and the best data quality. Ongoing improvements to the APIs for data entry, and to the tools for monitoring data quality, could certainly help here, as would increased engagement with e-procurement system vendors to get them to bake open contracting into their platforms, as Chris Smith has called for.
However, as we head in 2018, whilst we have to keep working on policy and platforms – the real focus needs to be on implementation: monitoring and motivating each department or public agency to be sure they are not only seeing transparency in procurement as a tick-box compliance excercise, but instead making sure it is embraced as a core part of accountable and open government. To date, Open Contracting in the UK has been the work of a relatively small network of dedicated officials, activists and entrepreneurs. If the vibe at OC Global last month was anything to go by, 2018 may well be the year it moves into the mainstream.
Disclosure/notes
I’m a member of the UK Open Contracting Steering Group, working under Commitment 5 of the UK OGP plan and I work for Open Data Services Co-op as one of the Open Contracting Data Standard helpdesk team.
 The online and open access book versions ‘The State of Open Data: Histories and Horizons’ went live yesterday. Do check it out!
The online and open access book versions ‘The State of Open Data: Histories and Horizons’ went live yesterday. Do check it out!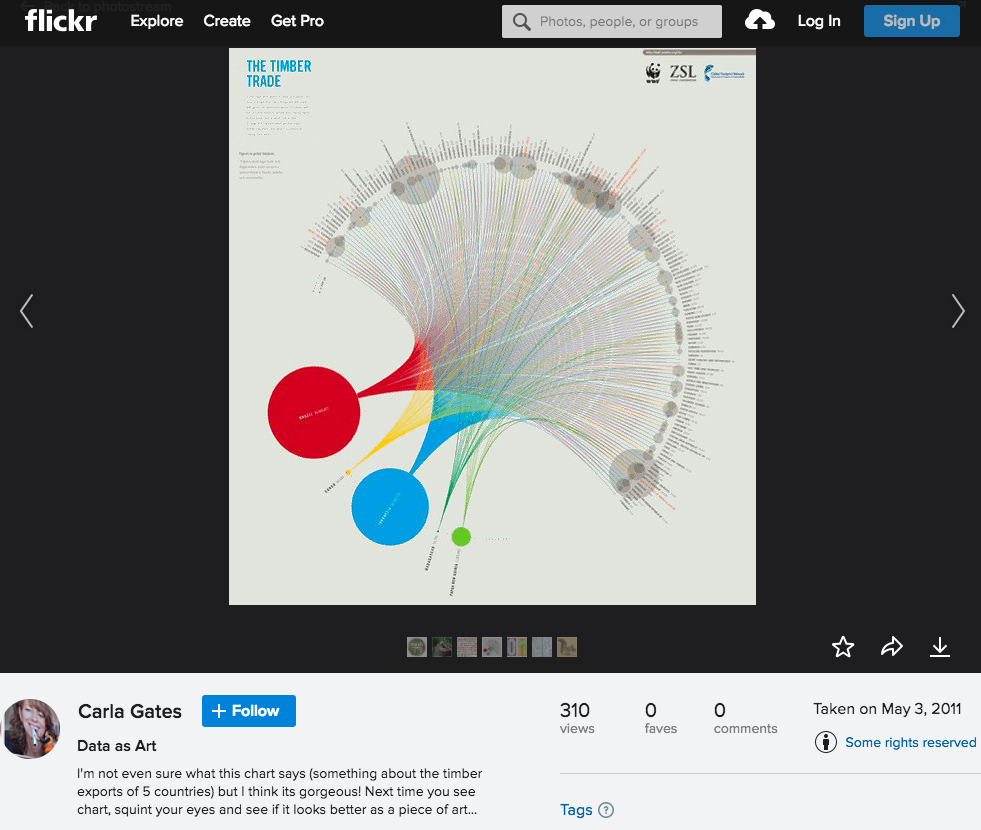











{kind=link}