It’s been a week of both thinking big about how we might, in the coming months and years, shift public and policy narratives about collective data governance, and focussing in on the details of what it might mean in practice to make data governance more participatory. In the iterative process of building out our case study database, and reviewing reports from a number of public dialogues, citizen’s juries and participatory processes linked to data governance, I’ve been reflecting on three themes, outlined under inevitably alliterative headings below.
At the same time, the Ada Lovelace review finds that “more research is needed on what the public expects ‘better’ regulation to look like” and ”determining what constitutes ‘public benefit’ from data requires ongoing engagement with the public”.
Having noticed that a lot of the cases I’ve gathered so far of public dialogue around data governance tend to inform, or design, fairly general principles or recommendations on how data should be handled, I’m finding it useful to think about participatory data governance on two levels:
1) How should public input shape the defaults that are in place for any uses of data?
There may be different defaults for different sectors, or potentially for different user groups (although Afsaneh Rigot’s recent report on Design from the Margins would suggest there are strong advantages in setting the overall default based on the needs of those most affected by a technology).
Not every organisation with data to govern will necessarily need to run its own engagement process to identify the right defaults: in many cases, desk research might identify clear public-backed principles to work with.
The legitimacy of any defaults may be affected by the extent to which they are derived from considering the particular impacts that a category or type of data may have, and the extent to which populations and communities affected by those impacts were part of developing the defaults.
2) What are the appropriate mechanisms for public engagement in the specific decisions that put those defaults into practice?
Where default setting might be periodic or one-off, there are many aspects of data governance which require day-to-day engagement. Where broad public engagement might be important for setting defaults, making decisions might require more focussed approaches, potentially with participants who have more background, training or ongoing role. I’m particularly interested in the coming weeks to try and explore different models being applied to data governance here: whether focussed on shaping decisions, sharing decisions, or providing scrutiny to decisions made.
The purpose of participation
I’ve been thinking a lot this week about the distinction between different institutional designs for data governance (including novel proposals for trusts, commons and co-ops), and questions of how decisions actually get made whatever the institutional structure. I was particularly struck by this critical piece from Rachel Adams at Research ICT Africa on the problems of reaching for a data trusts model in an African context.
I’ve found it helpful (this week at least!) to break down my thinking as follows:
Fundamentally, participation aims to align the outcomes of any process with the interests of those affected by it.
(This is compatible with recognising that some interests, and the way people or communities understand or articulate them, are not fixed, and may be refined or revised through participatory process).
In the context of democratically governed public authorities, competitive markets, and/or a balance of power between actors, then participatory processes can help to align the interests of data powers and communities; but
In conditions of vastly unequal power, other institutional mechanisms are required to create conditions in which the interests of authorities or firms and communities will end up aligned.
Mechanisms, for example, like trusts, commons or co-ops that seek to change where decisions are made, and what the backstops are to protect against individual, private or external interests being put above community or collective interests.
Thinking about the purpose of participation in terms of aligning actions or outcomes from data governance with the interests of the populations affected also brings into relief the points that (a) different communities may have interests that are not aligned, or even entirely compatible; and (b) a lot hinges on how the community whose interests are to be explored is defined.
Components, connections and configurations
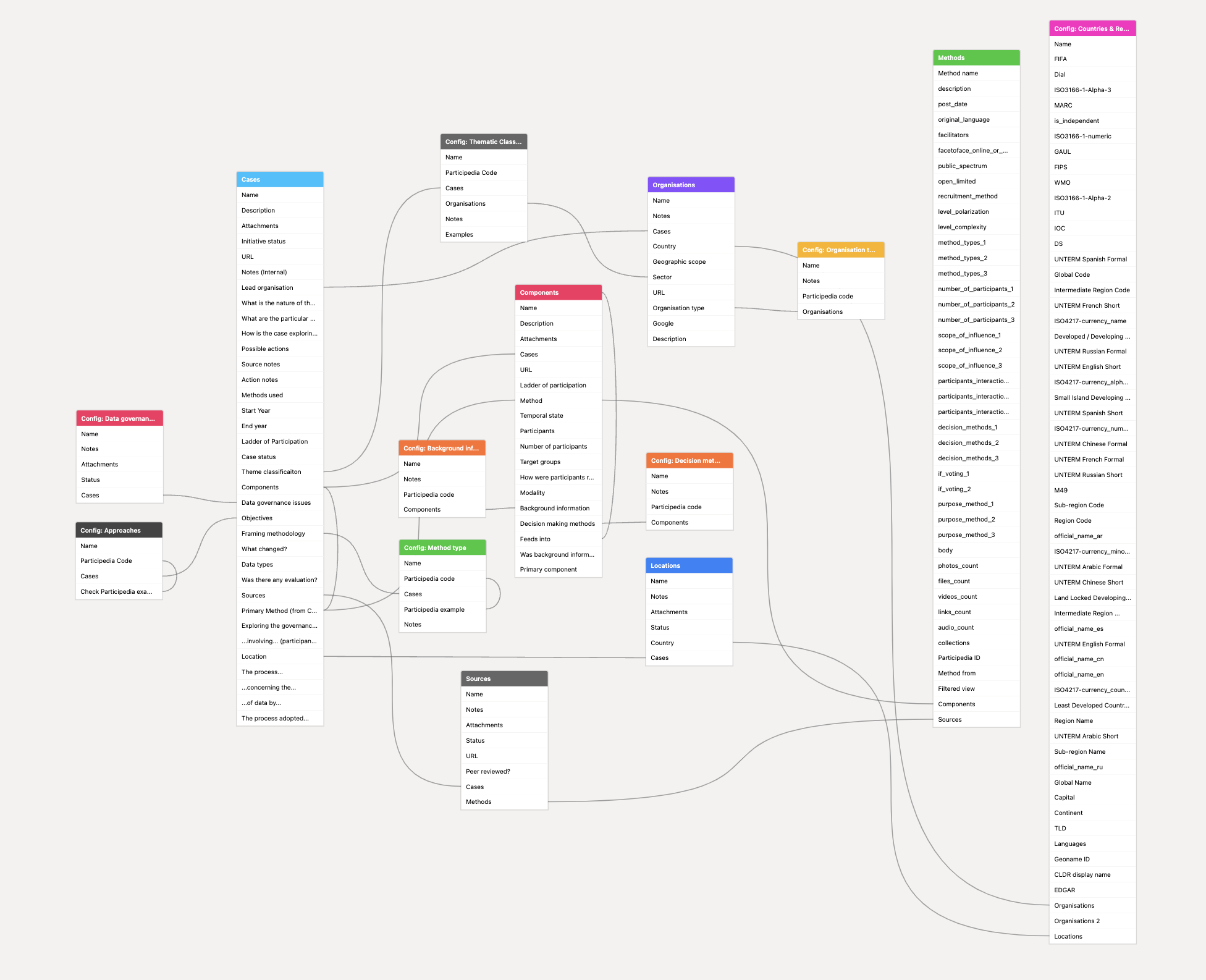
I’ve been starting to reflect on how to present the relationship between different parts of the participatory data governance cases I’ve been gathering. The case study schema has each case with multiple components that feed into each other, so that, for example, a citizens jury case might be broken down into the initial desk review and design, feeding into a set of roundtables that design materials, which are then used by main jury events, and which feed into an analysis process that produces a report. I’ve been thinking about whether it is useful to present this schematically (essentially a graph of the component relationships), and how this might also start to show where the participation process interfaces with organisational decisions. I might manage to get a quick prototype sorted soon.
Other stuff
I’ve also been:
Preparing an activity to think about our Theory of Change for the team offsite next week;
Setting up a Zotero group to keep track of Connected by Data literature;
Working up a session proposal for a roundtable on Collective Data Governance for the 2022 Internet Governance Forum (Nov 28th – 2nd Dec). An open draft of the proposal is here. We have got a good panel coming together – but I’m still looking for potential participants to include who might be thinking about collective data governance from within private sector or governments;
Starting a first few chats with researchers whose work touches on issues of participatory or collective data governance;
It’s been a busy week, not least because on Wednesday the project I was working on just before joining the Connected by data team, the Global Data Barometer, had its launch event. Alongside sharing, celebrating and reflecting on the Barometer, I’ve been digging deep into the development of a schema for our work to gather examples of collective data governance, and I’ve been thinking about potential events and convenings Connected by data might be part of in the coming year. Plus writing up some thoughts on what the implementation of social audits for India’s rural employment scheme in Andhra Pradesh can teach us about data governance, an initial bit of work on fundraising, and sending the first of many emails out to set up conversations with researchers I’m hoping to get some input from.
Cases, components and templates
I’ve been going through daily iterations to develop the structure for our case study database, taking a couple of different approaches to explore the right prompts, categories and structures that might create a useful library of collective data governance examples. I’ve been exploring:
adding the classification categories, and library of methods, from Participedia as lookup tables, and using them as a starting point, but adding/expanding categories when needed. This has been particularly useful when it comes to methods, as when I’m considering coding a case against a given method I can check the detailed Participedia description to check whether the code is appropriate. I’ve also set-up one-click searching so I can see if the way I initially think a category should be used matches how it has been used by Participedia contributors.
coding up one case each day, and, if needed, modifying the case database schema to capture it better, before going back to re-code existing cases with the modifications. This has led to a ‘case’, ‘component’ and ‘method’ separation, so that any case of collective data governance might involve multiple components (e.g. design workshops; citizens jury & opinion polling), and these are each treated as particular cases of applying one or more participatory methods.
drafting user stories (‘As an X I need Y so that Z’) to get a clearer sense of who the case database is for, and why. Thinking about the categories and data that users might actually want provides a useful counterbalance to the temptation to keep adding fields and more nuance when starting from reading diverse individual cases.
writing out a templated summary paragraph for a case, and then working out the different variables needed to populate it. I’ve found it particularly useful to then frame the prompts in the case database around these sentence components, making it easier to think about how each category will be used when the case database is made available to others.
Next week I’ll be trying to get a few more cases documented, and then to start exploring strategies to make sure we cover a wide range of kinds of examples. Right now, the examples I’ve coded up, and those in the pipeline, have a strong leaning towards participatory processes that generate quite general recommendations, rather than processes that directly shape or make specific data governance decisions.
Events and outreach
I started the week by registering forRightsCon, which is taking place online from 6 – 10th June. It’s a long time since I’ve been able to focus on attending a conference, rather than juggling logging into one or two virtual sessions between other work, so I’m looking forward to that.
On our discord I raised the possibility of proposing a workshop to the 2022 Internet Governance Forum on Collective Data Governance, and I’ll be sketching that out more next week and looking to see if we have potential collaborators.
We’ve also been starting to think about other potential events or outreach activities we might want to plan for, and I’ve done some initial work on research fundraising strategy: although realising I’ve got quite a bit of work to do in order to identify how to best track research funding opportunities that are well-aligned with what we want to do.
Participation, pluralism and the public good
I put out a thread of reflections on the launch of the Global Data Barometer, but want to pick up in particular on one in these notes. The Barometer study is framed around “data for the public good”. One of the big conceptual challenges for the design of the project which was taking place in 2019/2020, was balancing demands for cross-country comparison, with an openness to diversity of data governance, provision and use practices.
In the introduction to the report we wrote:
“Fundamentally, our approach to the public good recognizes that the construction of public good is an ongoing, unfinished and contested process. “
And
“There are many publics, many different visions of how society should be organized, and there are many views on the goals we should individually and collectively work towards.”
But, particularly after starting to read a copy of Pluriverse – a post development dictionary which arrived last week, I’m not sure the more pluralist ambitions of the project were fully realised (understandably so). With hindsight, and the framings of Connected by data, I suspect some of that might have been addressed by giving greater prominence to questions of participation in metrics on data governance.
However, the Barometer method also required each metric to make reference to globally agreed norms or principles that would support country assessment on that point. This raises the interesting question of which global norms can already ground a collective and participatory model of data governance, and where there are significant policy gaps that might need addressing to put communities at the heart of data governance.
Other reading this week
Bussu, S. et al. (2022) ‘Embedding participatory governance’,Critical Policy Studies – a compelling case to talk about embedding, rather than (or in addition to) institutionalising participatory governance, considering temporal (sustained over time), spatial (including presence of participation in different decision making spaces) and practice (habitual recourse to participatory process) dimensions of embeddedness.
Van de Velde, L. (2022) Gender and Beneficial Ownership Transparency– paper from Open Ownership that explores some of the tensions in designing datasets, particularly when it comes to the potential for data collected for one task (beneficial ownership transparency), to be used for other public goods (e.g. promoting greater gender equity in enterprise). I’m curious how a more collective and participatory data governance lens might help address some of the issues the paper explores. But – ran out of time to explore that in depth.
[Summary: new role focussing on participatory data governance, and starting to write weeknotes]
Last week I started a new role as Research Director for Connected by data, a new non-profit established by Jeni Tennison to focus on shifting narratives and practice around data governance. It’s a dream job for me, not least for the opportunity to work with Jeni, but also because it brings together two strands that have been woven throughout my work, but that I’ve rarely been able to bring together so clearly: governance of technology and participatory practice.
You can find the Connected by data strategic vision and roadmap here describing our mission to “put community at the centre of data narratives, practices and policies”, and our goals to work on challenging individual frameworks of data ownership, whilst showing how collective models offer a clearer way forward. We’ll also be developing practical guidance that helps organisations to adopt collective and participatory decision making practice, and a key focus for the first few weeks of my work is on building a library of potential case studies to learn from in identifying what works in the design of more participatory data governance.
Jeni’s organisational designs for Connected by data include a strong commitment to working in the open, and one of the practices we’re going to be exploring is having all team members produce public ‘weeknotes’ summarising activities, and most importantly, learning from the week. You can find the full of weeknotes over here, but in the interests of trying to capture my learning here too (and inviting any feedback from anyone still following this blog), I’ll try and remember to cross-post here too.
Last week’s weeknotes (6th May)
Hello! It’s the end of my first week as Research Director (and with the May day holiday in the UK, it’s been a short week too). I’ve been getting stuck into the research strand of the roadmap, as well as checking off some of the more logistical tasks like getting different calendars to talk to each other (calmcalendar to the rescue), posting my Bio on the website here, and setting up new systems. On that note, thanks to Jeni for the tip on logseq which seems to be working really nicely for me so far as both a knowledge-base, and a journal for keeping track of what’s happened each week to make writing up weeknotes easier.
The week has been bookended by scoping out how we’ll develop case studies of where organisations have adopted participatory approaches in data governance. I’ve started an AirTable dataset of potential case leads, and have been looking at if/how we could align some of our data collection with the data model used by Participedia (an open wiki of participation cases and methods). Over the next few weeks I’m anticipating an iterative process of working out the questions we need to ask about each case, and the kinds of classifications of cases we want to apply.
The middle of the week was focussed on responding to a new publication from the Global Partnership on Sustainable Development Data’s Data Values Project: a white paper on Reimagining Data and Power. The paper adopts a focus on collective engagement with data, and on participatory approaches to data design, collection, governance and use, very much aligned with the Connected by data agenda. Not only was the paper a source of a number of potential case study examples, but it also prompted a number of useful questions I’m hoping to explore more in coming weeks around the importance/role of data literacy in participatory data governance, and the interaction of what the paper terms ‘informal’ participatory models, with formal models of regulation and governance. Some of those thoughts are captured in this twitter thread about the report, and this draft response to the Data Values Project consultation call for feedback.
I also spent some time reviewing Jeni’s paper on ‘What food regulation teaches us about data governance’, and reflecting in particular on how the food analogy works in the context of international trade, and cross-border flows.
Finally, I’ve been helping the Global Data Barometer team put some finishing touches to the first edition report which will (finally!) launch next week. Although I handed over the reigns on the Global Data Barometer project to Silvana Fumega in the middle of last year, I’ve been back working on the final report since December: both on the data analysis and writing, and, trying (not always successfully) to have a reproducible workflow from data to report. Data governance is one of the key pillars of the report: although in the first edition there is relatively little said about _participatory _approaches, at least on the data creation and governance side. I’ll aim to write a bit more about that next week, and to explore whether there are missing global metrics that might help us understand how far a more collective approach to data is adopted or enacted around the world.
I was involved in setting up the Barometer project back in 2019/2020, and had the privilege of coming back into the project in December to work on the final report.
It’s already encouraging to see all the places the Barometer findings and data are being picked up, and whilst getting the report out feels like the finish line for, what has been, both marathon and sprint for the team – having the data out there for further analysis also feels like the starting line for lots of deeper research and exploration.
In particular, it feels like debates about ‘data for the public good’ have been developing at pace in parallel to the Barometer’s data collection, and I’m keen to see both how the Barometer data can contribute to those debates, and what future editions of the project might need to learn from the way in which data governance debates are shaping up in 2022.
I was involved in civil society aspects of developing of the UK’s 2nd and 3rd NAPs, and have written critiques of the others, so, although I’ve had minimal involvement in this NAP (I attended a few of the online engagement sessions, mainly on procurement transparency commitments, before they appeared to peter out) I thought I should try and unpack this one in the same kind of way.
By way of context, it’s a very tough time to be trying to advance the open government agenda in the UK. With Sue Gray’s report, and Prime Ministerial responses to it today, confirming the lack of integrity and the culture of dishonesty at the very centre of Number 10; just over a week after a ministerial resignation at the despatch box over government failures to manage billions of pounds of fraud during the COVID response; and on the day that government promised to pursue a post-Brexit deregulatory agenda; we have rarely faced a greater need, yet a less hospitable environment, for reforms that can strengthen checks and balances on government power, reduce space for corrupt behaviour, and bring citizens into dialogue about solving pressing environmental, social and political problems. As a key Cabinet Office civil servant notes, it’s a credit to all involved from the civil service and civil society, that the NAP was published at all in such difficult circumstances. But, although the plans’ publication shows that embers of open government are still there in Whitehall, the absence of a ministerial foreword, the lack of ambition in the plan, and the apparent lack of departmental ownership for the commitments it does contain (past plans listed the responsible stakeholder for commitments; this one does not), suggests that the status of open government in the UK, and the political will to take action on government reform within the international framework of the OGP, has fallen even further than in 2019.
When I wrote about the 2019 plan, I concluded that “The Global OGP process is doing very little to spur on UK action”. Since then, the UK has been called out and placed under review by the OGP Criteria & Standards Subcommittee in 2021 for missing action plan deadlines, and falling short of minimum requirements for public involvement in NAP development. Today’s published plan appears to admit that not enough has yet been done to rectify this, noting that:
In order to meet this criteria the government will amend and develop the initial commitment areas in NAP5 with civil society over the course of 2022.
Notably, past promises to civil society of adding to commitments to the NAP after the OGP deadline were not met (in part, if I recall correctly, because of issues with how this would interact with the OGP’s Independent Review Mechanism process), and so, with this line, civil society have a tactical choice to make: whether to engage in seeking to secure updates to the plan with assurance these will be taken forward, or whether to focus on ‘outsider’ strategies to put pressure on future UK OGP engagement. As Gavin Freeguard writes, we may be running up against the limits of “a one-size-fits-all international process that can’t possibly fit into the rhythms and rituals of UK government”. If this is so, then there is a significant challenge ahead to find any other drivers that can help secure meaningful open governance reforms in the UK: recognising that the coming years may be as much about the work of shoring up, and repair, as about securing grand new commitments.
A look at NAP5 commitments
Given the wider context, it hardly seems worth offering a critique of the individual commitments (but, erm, I ended up writing one anyway…) . It’s certainly difficult to extract any sense of a SMART (Specific, Measurable, Achievable, Realistic, Time-bound) milestone from any of them, and those that do appear to have some sort of measurable target betray a woeful lack of ambition*.
Take for example “publishing 90% of ‘above threshold’ contract awards within 90 days calendar days [of award presumably]”. Not only does that leave absolutely massive loopholes (any contract that it would be convenient not to publish could fall into the 10%; and 90-days takes disclosure of information on awards far beyond the period during which economic operators who lose out on a bid could be able to challenge a decision), but, this is more or less a commitment rolled over from the last National Action Plan. Surely, with the learning from the last few years of procurement scandals, and learning from the fact that Open Contracting commitments from the past have been poorly implemented, a credible National Action Plan would be calling for wholesale reform of procurement publication, following other OGP members who make award publication a binding part of a contract being enforceable, or invoices against it payable?
(*To be clear: I believe the vast majority of the fault for this lies with Ministers, not with the other individuals inside and outside government who have engaged in the NAP process in good faith).
with internal and external stakeholders to gauge the feasibility of conducting a scoping exercise focused on mapping existing legal requirements for appeal mechanisms, for example due to administrative law, data protection law, or domain-specific legislation; with a view to sharing this information with the public. [my emphasis]
If I’m reading this right that could well be: a conversation with unspecified stakeholders to gauge whether it’s even possible to work out the scope of a mapping that then may or may not take place, may nor may not be comprehensive, and may or may not result in outputs shared with the public. Even read more charitably (let’s assume the scoping exercise involves the mapping. not just scopes it!), surely the point of the National Action Plan development process is have the conversations with internal and external stakeholders to ‘gauge the feasibility’ of an open government action taking place?
Others have commented on the backsliding in commitments to Open Justice, and I’ll leave it to those more involved at present in combatting the UK’s role in Illicit Financial Flows to comment on the limited new commitments there. However, I do want to pick up two comments on the health section in the NAP. Firstly, while inclusion of health within the NAP, as a topic much more legible in many people’s daily lives (and not only in the last two years) than topics like procurement or stolen asset recovery, is broadly welcome, the health section betrays a worrying lack of distinction between:
• Patient data;
• Health system data;
The State of Open Data: Histories and Horizon’s chapter on Health offers a useful model for thinking about this. In general, Open Government should be concerned with planning and operational data, service information, and research outputs. Where open government and personal data meet, it should be about the protection of individuals data rights: recognising elements of citizen privacy as foundational for open government.
In practice, when we talk of transparency, we need to be very clear to distinguish transparency about how (personal) health data is used (generally a good thing), and transparency of (personal) health data (usually a sign that something has gone profoundly wrong with data protection!). To talk about transparency of health data without qualifiers risks messy policy making, and undermining trust in both open government and health data practices. After reading it over a few times, I *think* ‘Objective 1: accountability and transparency’ under the health heading is about being transparent and accountable about how data is used, but there is little room for sloppy drafting in these matters. The elision of agendas to create large health datasets (with mixed public and private-sector users), with the open government agenda, has been something civil society have had to be consistently watchful of in the history of UK NAPs, and it appears this time around is no different.
Secondly, and perhaps related, it’s not at all clear to me why a a “standards and interoperability strategy for adoption across health and adult social care” (under Health ‘Objective 2: Data standards and interoperability’) belongs in an Open Government National Action Plan. Sure, the UK health system could benefit from greater interoperability of clinical systems, and this might have an impact on patient welfare. But the drivers for this are not open government: they are patient care. And an OGP National Action Plan is going to do little to move the needle on a challenge that the health sector has been tackling for decades (I recall conversations around the dining room table with my Dad, then an NHS manager, twenty years ago, about the latest initiatives then to move towards standardised models for interoperable patient data and referrals).
It might seem hair-splitting to say that certain reforms to government fall outside the scope of open government, but for the concept to be meaningful it can’t mean all and any reform of government systems. If we were talking about ways of engaging citizens in the design process for interoperability standards, and thinking critically about the political and social impact that categorisations within health records have, we might have something worthy of an open government plan, but we don’t. Instead, we have an uncritical focus on centralising data, and a development approach that will only involve “vendors, suppliers, digital technologists, app developers and the open source community”, but not actual care-service users, or people affected by the system design*.
(*I know that in practice there are many fantastic service and technology designers around the NHS who are both critically aware of the cost and benefit tradeoffs of health system interoperability, and a personal/professional commitment to work with service users in all design work; but the absence of service-users from the text of the NAP commitment is notable.)
Lastly, the plan includes a placeholder for forthcoming commitments on “Local transparency”, to be furnished by the Department for Levelling Up, Housing and Communities (DLUHC) sometime in 2022. In past rounds of the NAP, civil society published a clear vision for the commitments they would like to see under certain headings, and the NAP has named the civil society partners working to develop and monitor commitments. Not this time around it seems. Whilst OGP colleagues in Northern Ireland have been running workshops to talk about open local government, I can’t find evidence of any conversations that might show what might fall under this heading when, or if, the current Westminster NAP evolves.
Still looking for a way forward…
As I wrote in 2019, I generally prefer my blogging (and engagement) to be constructive: but that’s not been easy recent Open Government processes in the UK. At the same time, I did leave a recent session on ‘The (Absolute) State of Open Government’ at the latest UKOpenGovCamp unconference feeling surprisingly optimistic. Whilst any political will from the Conservative government for meaningful open government is, at least at present, sorely lacking, open working cultures within some pockets of government seem to have been remarkably resilient, and even appear to have deepened over the course of the pandemic. The people of open government are still there, even if the political leadership and policies are missing in action.
All the ambitious, necessary, practical and SMART commitment ideas that didn’t make it into this NAP need to be implementation-ready for any openings for reform that may come in the volatile near-future of UK politics. Just as civil society successfully used the UK’s Chairmanship and hosting of the OGP Summit back in 2012/13 to lock in stronger open beneficial ownership data commitments, civil society needs to be ready with ideas that, while they may get no traction right now, might find an audience, moment and leverage in future – at least if we manage to protect and renew our currently fragile democratic system.
I’ve long said that the OGP should be a space for the UK to learn from other countries: forgoing ideas of UK exceptionalism, and recognising that polities across the world have grapled with the kinds of problems of populist and unaccountable leadership we’re currently facing. As I work on finalising the Global Data Barometer Report, I’ll be personally paying particular attention to the ideas and examples from colleagues across OGP civil society that are particularly relevant to learn from.
And if you are in anyway way interested in open government in the UK, even though the process right now feels rather stuck and futile, you can sign-up to the UK civil society Open Government Network mailing list to be ready to get involved in revitalising open government action in the UK when the opportunity is there (or, perhaps, when we collectively make it arise).
Over the last week I’ve been sharing a short series of articles exploring the past, present and future of (open) data portals. This comes as part of a piece of work I’m doing for the Open Data Institute on ‘Data Platforms and Citizen Engagement’.
The work starts from the premise that data portals have been an integral part of the open data movement. Indeed, for many (myself included) the open data movement was crystallised with, or first discovered through, the launch of platforms like Data.gov and Data.gov.uk. However, we are going on to ask whether, a decade on, portals still have a role to play? And if so, what might that role most usefully be? Ultimately, we’re asking if, and if so, how, portals might be (re-)shaped as effective platforms to support ongoing ambitions for open data to support meaningful citizen participation in all its forms.
Over the course of a short rapid research sprint I’ve been pulling at a couple of threads that might contribute to that inquiry. The goal has been to carry out some groundwork to support the next stage of the project: which we are hoping will take the form of some sort of design excercises, accompanied by a number of deeper conversations and possibly further research. I overshot my initial plan of spending five days ‘catching up’ with what’s been happening in the portal landscape since I last looked, not least because the simple answer is – a lot’s been happening. And, at the same time, if you compare a portal from 2012 with the same one today, the answer to the question ‘What’s changed?’ often also seems to be, not very much. The breadth and depth of work constructing and critiquing portals across the world is both impressive, and oppressive. It seems that, collectively, we know there are problems with portals, but, there is much less consensus on the way forward.
Each post in this series has tried to look at ‘the portals problem’ from one specific perspective, aiming to provide some shared context that might assist in future conversations. The posts are all over on PubPub, where they’re open to comment (free sign-up needed):
If, after exploring some of these, you think you might be interested in joining some of the open design sprint work we’re planning for next year to build on this exploration – and on parallel strands of research that have been taking place (likely involving some online or in-person full and half-day sessions in early Feb) do drop me a line via twitter or (for this project only) my ODI e-mail address: tim.davies@theodi.org and I can share more info as plans firm up.
I’m cross-posting this from a deep-dive series of working drafts I’ve been developing for The Open Data Institute, providing ground work for exploring potential future developments that could support data portals and platforms to function better as tools of civic participation. It provides a general history of the development of citizen participation, primarily in the UK context, that I hope may be of interest to a wide range of readers of this blog, as well as setting this in the context of data portals as participation tools (possibly more of a niche interest..). You can find the full series of posts which talk a lot more about data portals, here.
A key cause of data portal dissatisfaction is the apparent failure of portals to provide effective platforms for citizen participation in government and governance. The supposed promise of portals to act as participatory platforms can be read into the 2009 Obama Open Government Memo on transparent, participatory and collaborative government, and the launch of data.gov.uk amongst the hackathons and experiments with online engagement that surrounded the Power of Information report and taskforce. Popular portal maturity models have envisioned them evolving to become participatory platforms [1][2] and whilst some work has acknowledged that there are different forms of participatory engagement with the state, ranging from monitorial democracy, to the co-production of public services [3], the mechanisms by which portals can help drive participation, and the forms of participation in focus, have been frequently under-theorised.
In the current policy landscape, there is a renewed interest in some forms of participatory engagement. Citizens assemblies, deliberative fora, and other forms of mini-public are being widely adopted as ways to find or legitimate ways forward on thorny and complex issues. Amidst concerns about public trust, democratic control, and embedded biases, there are calls for participatory processes to surround the design and deployment of algorithmic systems in particular [4], creating new pressure on participatory methods to engage effectively with data. However, public participation has a long history, and these latest trends represent just one facet of the kinds of processes and modes of engagement we need to have in mind when considering the role of data portals in supporting citizen engagement. In this short piece I want to briefly survey the history of public participation, and to identify potential insights for the development of data portals as a support for participatory processes. My focus here is primarily on the UK landscape, although I’ll try and draw upon wider global examples where relevant.
A short history of citizen participation
In the blog post ‘A brief history of participation’, historian Jo Guldi explores the roots of participatory governance ideas, tracing them as far back as the early mediaeval church, and articulating ideas of participatory governance as a reaction to the centralised bureaucracies of the modern nation state. Guldi points to the emergence of “a holistic political theory of self-rule applicable to urban planning and administration of everyday life” emerging in the 1960s, driven by mass youth movements, mass media, and new more inclusive notions of citizenship in an era of emerging civil rights. In essence, as the franchise, and education, expanded, default models of ‘elite governance’ came to be challenged by the idea that the public should have a greater voice in day to day decision making, if not greater direct ownership and control of public authority.
In Guldi’s global narrative, the emphasis of the 1970s and 80s was then on applying participatory ideas within the field of International Development, particularly participatory mapping – in which marginalised citizens are empowered to construct their own maps of territory: in a sense creating counter-data to secure land rights, and protect customary resources from logging or other incursions. Guldi points in particular to the role of institutions such as the World Bank in promoting participatory development practises, a theme also found in Leal’s ‘Participation: the ascendancy of a buzzword in the neo-liberal era’ [5]. Leal highlights how, although participatory methods have their roots in the emancipatory pedagogy of Paulo Friere and in Participatory Action Research, which aims at a transformation of individual capabilities alongside wider cultural, political and economic structures – the adoption of participation as a tool in development can act in practice as a tool of co-option: depoliticising critical decisions and offering participants only the option to modify, rather than fundamentally challenge, directions of development. Sherry Arnstein’s seminal ‘A ladder of citizen participation’ article[6], published in 1969 in an urban planning journal, has provided a reliable lens for asking whether participation in practice constitutes decoration, tokenism, or genuine citizen power.
Illustration of the ladder of participation from Arnstein’s original article, showing eight rungs, and three categories of participation, from ‘nonparticipation’, to ‘degrees of tokenism’ and up to ‘degrees of citizen power’.
In the UK, whilst radical participatory theory influenced grassroots community development work throughout the 1980s, it was with the election of the New Labour Government in 1997 that participation gained significant profile in mainstream policy-making: with major initiatives around devolution, the ‘duty to consult’, and an explosion of interest in participatory methods and initiatives. Fenwick and McMillan describe participation for New Labour as ‘something at the heart of the guiding philosophy of government’, framed in part as a reaction to the consumer-oriented marketised approach to public management of the Thatcher era. Yet, they also highlight a tension between an ideological commitment to participation, and a managerial approach to policy that sought to also ‘manage’ participation and its outcomes. Over this period, a particular emphasis was placed on participation in local governance, leading top-down participation agendas to meet with grassroots communities and community development practices that had been forged through, and often in opposition to, recent decades of Conservative rule. At its best, this connection of participatory skill with space to apply it provided space for more radical experiments with community power. At its worst, and increasingly over time, it led to co-option of independent community actors within state-directed participation: leading ultimately to a significant loss of both state-managed and community-driven participatory practice when the ‘era of austerity’ arrived in 2010.
The 2000s saw a proliferation of guides, handbooks and resources (e.g.) outlining different methods for citizen participation: from consultation, to participatory budgeting, citizens panels, appreciative inquiries, participatory research, and youth fora. Digital tools were initially seen broadly as another ‘method’ of participation, although over time understanding (albeit still relatively limited) has developed of how to integrate digital platforms as part of wider participatory processes – and as digital development has become more central in policy making, user-involvement methodologies from software development have to be critically considered as part of the citizen participation toolbox. Concepts of co-production, co-design and user-involvement in service design have also increasingly provided a link-point between trends in digital development and citizen participation.
Looking at the citizen participation landscape in 2021, two related models appear to be particularly prominent: deliberative dialogues, and citizens assemblies. Both are predicated on bringing together broadly representative groups of citizens, and providing them with ‘expert input’, generally through workshop-based processes, and encouraging deliberation to inform policy, or to generate recommendations from an assembly. Notably, deliberative methods have been adopted particularly in relation to science and technology, seen as a way to secure public trust in emerging scientific or technological practice, including data sharing, AI and use of algorithmic systems. Whilst deliberative workshops and citizens assemblies are by no means the only participatory methods in use in 2021, they are notable for their reliance on expert input: although the extent to which direct access to data features in any of these processes is perhaps a topic for further research.
By right, or by results
Before I turn to look specifically at the intersection of data and participation, it is useful to briefly remark on two distinct lines of argument for participation: values or rights-based, vs. results based.
The rights-based approach can be found both in theories of participatory democracy that argue democratic mandate is not passed periodically from voters to representatives, but is constantly renewed through participatory activities engaging broad groups of citizens, and in human-rights frameworks, including notably the UN Convention on the Rights of the Child (UNCRC), which establishes children’s rights to appropriate participation in all decisions that affect them. Guidance on realising participation rights adopted in 2018 by the UN Human Rights Council explicitly makes a link with access to information rights, including proactive disclosure of information, efforts to make this accessible to marginalised groups, and independent oversight mechanisms.
A results-based approach to citizen participation is based on the idea that citizen engagement leads to better outcomes: including supporting more efficient and effective delivery of public services, securing greater citizen trust in the decisions that are made, or reducing the likelihood of decisions being challenged. Whilst some user and human-centred design methodologies may make reference to rights-based justifications for inclusion of often marginalised stakeholders, in general, these approaches are rooted more in a result-based than a rights-based framework: in short, many firms and government agencies have discovered projects have greater chance of success when you adopt consultative and participatory design approaches.
Participation, technology and data
Although there have been experiments with online participation since the earliest days of computer mediated communication, the rise of Web 2.0 brought with it substantial new interest in online platforms as tools of citizen engagement: both enabling insights to be gathered from existing online social spaces and digital traces, and supporting more emergent, ad-hoc or streamlined modes of co-creation, co-production, or simply communication with the state (as, for example, in MySociety’s online tools to write to public representatives, or report street scene issues in need of repair). There was also a shift to cast the private sector as a third stakeholder group within participatory processes – primarily framed as originator of ideas, but also potentially as the target of participation-derived messages. As the Open Government Partnership’s declaration puts it, states would “commit to creating mechanisms to enable greater collaboration between governments and civil society organizations and businesses.”
With rising interest in open data, a number of new modes and theories of participation came to the fore: the hackathon [7][8][9], the idea of the armchair auditor [10], and the idea of ‘government as a platform’ [11][12] each invoke particular visions of citizen-state and private-sector engagement.
A focus in some areas of government on bringing in greater service-design approaches, and rhetoric, if not realities, of data-driven decision making have also created new spaces for particular forms of participatory process, albeit state-initiated, rather than citizen created. And recent discussions around data portals and citizen participation have often centred on the question of how to get citizens to engage more with data, rather than how data can support existing or potential topic-focussed public participation.
In my 2010 MSc thesis on ‘Open Data, Democracy & Public Sector reform: open government data use from data.gov.uk’ I developed an initial typology of civic Open Government Data uses, based on a distinction between formal political participation (representative democracy), collaborative/community based participation (i.e. participatory democracy or utility-based engagement), and market participation (i.e. citizen as consumer). In this model, the role data plays, and the mechanisms it works through, vary substantially: from data being used through media to inform citizen scrutiny of government, and ultimately discipline political action through voting; to data enabling citizens to collaborate in service design, or independent problem solving beyond the state; and to the consumer-citizen driving change through better informed choices of access to public services. In other words, greater access to data theoretically enables a host of different genres of participation (albeit there’s a normative question over how meaningful or equitable each of these different forms of participation are) – and many of these do not rely on the state hosting or convening the participation process.
What is notable about each of these ‘mechanisms of change’ is that data accessed from a portal is just one component of a wider process: be that the electoral process in its entirety, a co-design initiative at the community level, or some national market-mechanism supported by intermediaries translating ‘raw data’ into more accessible information that can drive decisions over which hospital to use, or which school to choose for a child. However, whilst many participatory initiatives have suffered in an era of austerity, and enthusiasm for the web as an open agora for public debate has waned in light of a more hostile social media environment, portals have persisted as a primary expression of the ‘open government’ era: leaving considerable pressure placed upon the portal to deliver not only transparency, but also participation and collaboration too.
Citizen participation and data portals
What can we take from this brief survey of citizen participation when it comes to thinking about the role of data portals?
Firstly, the idea that portals as technical platforms can meaningfully ‘host’ participation in its entirety appears more or less a dead-end. Participation takes many varied forms, and whilst portals might be designed (and organisationally supported) in ways that position them as part of participatory democracy, they should not be the destination.
Secondly, different methods of citizen participation have different needs. Some require access to simple granular ‘facts’ to equalise the balance of power between citizen and state. Others look for access to data that can support deep research to understand problems, or experimental prototyping to develop solutions. Whilst in the former case, quick search and discovery of individual data-points is likely to be the priority, in these latter cases, greater understanding of the context of a dataset is likely to be particularly valuable, as would, in many cases, the ability to be in contact with a datasets’ steward.
Third, the current deliberative wave appears as likely to have data as its subject (or at least, the use of data in AI, algorithmic systems or other policy tools), as it is to use open data as an input to deliberation. This raises interesting possibilities for portals to surface and support great deliberation around how data is collected and used, as a precursor to supporting more effective use of that data to drive policy making.
Fourth, citizen participation has rarely been a ‘mass’ phenomena. Various research suggest that at any time less than 10% of the population are engaged in any meaningful form of civic participation, and only a percentage of these are likely to be involved in forms of engagement that are particularly likely to benefit from data. Portals should not carry the burden of solving a participation deficit, but there may be avenues to design them such that they connect with a wider group of active citizens than their current data-focussed constituency.
Fifth, and finally, citizen participation is not invented with the portal – and we need to be conscious of both the long history, and contested conceptualisations, of citizen participation. The government portal that seeks to add participatory features is unlikely to be able to escape the charge that it is seeking to ‘manage’ participation processes: although independently created or curated portals may be able to align with more bottom-up community participation action and operate within a more emancipatory, Frierian notion. Both data, and participation, are, after all, about power. And given power is generally always contested, the configuration of portals as a participatory tool may be similarly so.
Citations
Alexopoulos, C., Diamantopoulou, V., & Charalabidis, Y. (2017). Tracking the Evolution of OGD Portals: A Maturity Model. In Lecture Notes in Computer Science (pp. 287–300). Springer International Publishing. https://doi.org/10.1007/978-3-319-64677-0_24
Zhu, X., & Freeman, M. A. (2018). An evaluation of U.S. municipal open data portals: A user interaction framework. Journal of the Association for Information Science and Technology, 70(1), 27–37. https://doi.org/10.1002/asi.24081
Ruijer, E., Grimmelikhuijsen, S., & Meijer, A. (2017). Open data for democracy: Developing a theoretical framework for open data use. Government Information Quarterly, 34(1), 45–52. https://doi.org/10.1016/j.giq.2017.01.001
Wilson, C. (2021). Public engagement and AI: A values analysis of national strategies. Government Information Quarterly, 101652. https://doi.org/10.1016/j.giq.2021.101652
Sieber, R. E., & Johnson, P. A. (2015). Civic open data at a crossroads: Dominant models and current challenges. Government Information Quarterly, 32(3), 308–315. https://doi.org/10.1016/j.giq.2015.05.003
Perng, S.-Y. (2019). Hackathons and the Practices and Possibilities of Participation. In The Right to the Smart City (pp. 135–149). Emerald Publishing Limited. https://doi.org/10.1108/978-1-78769-139-120191010
O’Leary, D. E. (2015). Armchair Auditors: Crowdsourcing Analysis of Government Expenditures. Journal of Emerging Technologies in Accounting, 12(1), 71–91. https://doi.org/10.2308/jeta-51225
The OECD digital government policy framework. (2020, October 7). OECD Public Governance Policy Papers. Organisation for Economic Co-Operation and Development (OECD). https://doi.org/10.1787/f64fed2a-en
[Summary: a critical look at the UK’s Algorithmic Transparency Standard]
I was interested to see announcements today that the UK has released an ‘Algorithmic Transparency Standard’ in response to calls recommendations from the Centre for Data Ethics and Innovation (CDEI)“that the UK government should place a mandatory transparency obligation on public sector organisations using algorithms to support significant decisions affecting individuals”, and commitments in the National Data Strategy to “explore appropriate and effective mechanisms to deliver more transparency on the use of algorithmic assisted decision making within the public sector”and National AI Strategy to“Develop a cross-government standard for algorithmic transparency.”. The announcement is framed as “strengthening the UK’s position as a world leader in AI governance”, yet, at a closer look, there’s good reason to hold out judgement on whether it can deliver this until we see what implementation looks like.
Here’s a rapid critique based purely on reading the online documentation I could find. (And, as with most that I write, this is meant in spirit of constructive critique: I realise the people working on this within government, and advising from outside, are working hard to deliver progress often on limited resources and against countervailing pressures, and without their efforts we could be looking at no progress on this issue at all. I remain an idealist, looking to articulate what we should expect from policy, rather than what we can, right now, reasonably expect.)
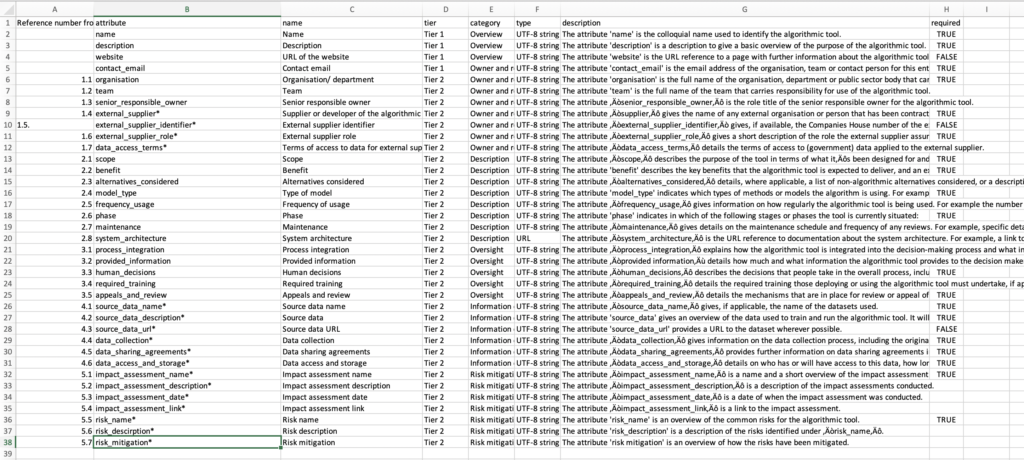
An algorithmic transparency data standard’ – which at present is a CSV file listing 38 field names, brief descriptions, whether or not they are required fields, and ‘validation rules’ (given in all but one case, as ‘UTF-8 string’);
An algorithmic transparency template and guidance described as helping ‘public sector organisations provide information to the data standard’ and consisting of a Word document of prompts for information that is required by the data standards.
Besides the required/non-required field list from the CSV file, there do not appear to be any descriptions of what adequate or good free text responses to the various prompts, or any stated requirements concerning when algorithmic transparency data should be created or updated (notably, the data standard omits any meta-data about when transparency information was created, or by whom).
The press release describes the ‘formalisation’ route for the standard:
Following the piloting phase, CDDO will review the standard based on feedback gathered and seek formal endorsement from the Data Standards Authority in 2022.
Currently, the Data Standards Authority web pages“recommends a number of standards, guidance and other resources your department can follow when working on data projects”, but appear to stop short of mandating any for use.
So, what kind of standard is the Algorithmic Transparency Standard?
Well, it’s not a quality standard, as it lacks any mechanism to assess the quality of disclosures.
It’s not a policy standard as it’s use is not mandated in any strong form.
And it’s not really a data standard in it’s current form, as it’s development has not followed an open standards process, it doesn’t use a formal data schema language, nor is it on a data standards track.
And it’s certainly not an international standard, as it’s been developed solely through a domestic process.
What’s more, even the template ultimately isn’t all that much of a template, as it really just provides a list of information a document should contain, without clearly showing how that should be laid out or expressed – leading potentially to very differently formatted disclosure documents.
And of course, a standard isn’t really a standard unless it’s adopted.
So, right now, we’ve got the launch of some suggested fields of information that are suggested for disclosure when algorithms are used in certain circumstances in the public sector. At best this offers the early prototype of a paired policy and data standard, and stops far short of CDEI’s recommendation of a “mandatory transparency obligation on public sector organisations using algorithms to support significant decisions affecting individuals”.
Press releases are, of course, prone to some exaggeration, but it certainly raises some red flags for me to see such an under-developed framework being presented as the delivery of a commitment to algorithmic transparency, rather than a very preliminary step on the way.
However, hype aside, let’s look at the two parts of the ‘standard’ that have been presented, and see where they might be heading.
Evaluated as a data specification
The guidance for government or public sector employees using algorithmic tools to support decision-making on use of the standard asks them to fill out a document template, and send this to the Data Ethics team at Cabinet Office. The Data Ethics team will then publish the documents on Gov.uk, and reformat the information into the ‘algorithmic transparency data standard’, presumably to be published in a single CSV or other file collecting together all the disclosures.
Data specifications can be incredibly useful: they can support automatic validation of whether key information required by policy standards has been provided, and can reduce the friction of data being used in different ways, including by third parties. For example, in the case of an effective algorithmic transparency register, standardised structured disclosures could:
Allow linking of information to show which datasets are in use in which algorithms, and even facilitate early warning of potential issues (e.g. when data errors are discovered);
Allow stakeholders to track when new algorithms are being introduced that affect a particular kind of group, or that involve a particular kind of risk;
Support researchers to track evolution of use of algorithms, and to identify particular opportunities and risks;
Support exchange of disclosures between local, national and international registers, and properly stimulate private sector disclosure in the way the press release suggests could happen;
However, to achieve this, it’s important for standards to be designed with various use-cases in mind, and engagement with potential data re-users. There’s no strong evidence in this case of that happening – suggesting the current proposed data structure is primarily driven by the ‘supply side’ list of information to be disclosed, and not be any detailed consideration of how that information might be re-used as structured data.
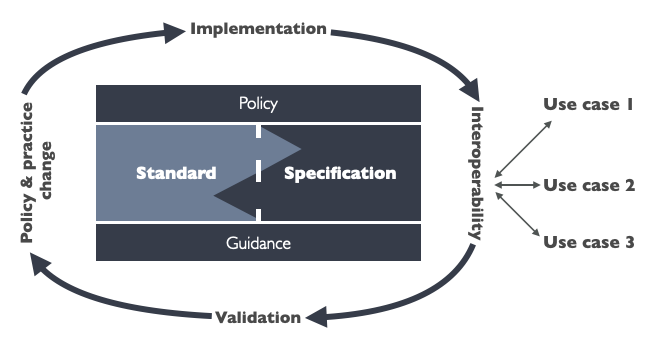
Modelling the interaction of data standards and policy standards (Source: TimDavies.org.uk)
Data specifications are also more effective when they are built with data validation and data use in mind. The current CSV definition of the standard is pretty unclear about how data is actually to be expressed:
Certain attributes are marked with * which I think means they are supposed to be one-to-many relationships (i.e. any algorithmic system may have multiple external suppliers, and so it would be reasonable for a standard to have a way of clearly modelling each supplier, their identifier, and their role as structured data) – but this is not clearly stated.
The ‘required’ column contains a mix of TRUE, FALSE and blank values – leaving some ambiguity over what is required (And required by who? With what consequence if not provided?)
The field types are almost all ‘UTF- string’, with the exception of one labelled ‘URL’. Why other link fields are not validated as URLs does not appear clear.
The information to be provided in many fields is likely to be fairly long blocks of text, even running to multiple pages. Without guidance on (a) suggested length of text; and (b) how rich text should be formatted; there is a big risk of ending up with blobs of tricky-to-present prose that don’t make for user-friendly interfaces at the far end.
Screenshot of current Algorithmic Transparency Data Standard
As mentioned above, there is also a lack of meta-data in the specification. Provenance of disclosures is likely to be particularly important, particularly as they might be revised over time. A robust standard for an algorithmic transparency register should properly address this.
Data is more valuable when it is linked, and there are lots of missed opportunities in the data specification to create a better infrastructure for algorithmic transparency. For example, whilst the standard does at least ask for the company registration number of external suppliers (although assuming many will be international suppliers, an internationalised organization identifier approach would be better), it could be also asking for links to the published contracts with suppliers (using Contracts Finder or other platforms). More guidance on the use of source_data_url to make sure that, wherever a data.gov.uk or other canonical catalogue link for a dataset exists, this is used, would enable more analysis of commonly used datasets. And when it comes to potential taxonomies, like model_type, rather than only offering free text, is it beyond current knowledge to offer a pair of fields, allowing model_typeto be selected from a controlled list of options, and then more detail to be provided in a free-text model_type_detailsfield? Similarly, some classification of the kinds of services the algorithm affects using reference lists such as the Local Government Service list could greatly enhance usability of the data.
Lastly, when defined using a common schema language (like JSON Schema, or even a CSV Schema language), standards can benefit from automated validation, and documentation generation – creating a ‘Single Source of Truth’ for field definitions. In the current Algorithmic Transparency Standard there is already some divergence between how fields are described in the CSV file, and the word document template.
There are some simple steps that could be taken to rapidly iterate the current data standard towards a more robust open specification for disclosure and data exchange – but that will rely on at least some resourcing and political will to create a meaningful algorithmic transparency registers – and would benefit from finding a better platform to discuss a standard than a download on gov.uk.
Evaluated as a policy standard
The question “Have we met a good standard of transparency in our use of X algorithm?” is not answered simply by asserting that certain fields of information have been provided. It depends on whether those fields of information are accurate, clearly presented, understood by their intended users, and, in some way actionable (e.g. the information could be drawn upon to raise concerns with government, or to drive robust research).
The current ‘Algorithmic transparency template’ neither states the ultimate goal of providing information, nor give guidance on the processes to go through in order to provide the information requested. Who should fill in the form? Should a ‘description of an impact assessment conducted’ include the Terms of Reference for the assessment, or the outcome of it? Should risk mitigations be tied to individual risks, or presented at a general level? Should a template be signed-off by the ‘senior responsible owner’ of the tool? These questions are all left unanswered.
The list of information to be provided is, however, a solid starting point – and based in relevant consultation (albeit perhaps missing consideration of the role of intermediaries and advocacy groups in protecting citizen interests). What’s needed to make this into a robust policy standard is some sense of the evaluation checklist that needs to be carried out to judge whether a disclosure is a meaningful disclosure or not and some sense of how, beyond pilot, this might become more mandatory and part of the business process of deploying algorithmic systems, rather than simply an optional disclosure (i.e. pilots need to talk about the business process not just the information provision).
Concluding observations
The confusion between different senses of ‘standard’ (gold standard, data standard) can deliver a useful ambiguity for government announcements: but it’s important for us to scrutinise and ask what standards will really deliver. In this case, I’m sceptical that the currently described ‘standard’ can offer the kind of meaningful transparency needed over use of algorithms in government. It needs substantial technical and policy development to become a robust tool of good algorithmic governance – and before we shout about this as an international example, we need to see that the groundwork being laid is both stable, and properly built upon.
On a personal level, I’ve a good degree of confidence in the values and intent of the delivery teams behind this work, but I’m left with lingering concerns that political framing of this is not leading towards a mandatory register that can give citizens greater control over the algorithmic decisions that might affect them.
[Summary: Fragments of reflection on the Decarbonisation and Decolonisation of AI]
I’ve spent some time this morning reading the ‘AI Decolonial Manyfesto’ which opens framed as “a question, an opening, a dance about a future of AI technologies that is decolonial”. Drawing on the insights, positions and perspectives of a fantastic collective authorship, it provides some powerful challenges for thinking about how to shape the future applications of AI (and wider data) technologies.
As I’ve been reading the Manyfesto on Decolonialisation in a short break from working on a project about Decabonisation – and the use of data and AI to mitigate and adapt to the pressing risks of climate breakdown, I find myself particularly reflecting on two lines:
“We do not seek consensus: we value human difference. We reject the idea that any one framework could rule globally.”
and
“Decolonial governance will recognize, in a way that Western-centric governance structures historically have not, how our destinies are intertwined. We owe each other our mutual futures.”
Discussions over the role of data in addressing the global climate crisis may veer towards proposing vast centralising data (and AI) frameworks (or infrastructures), in order to monitor, measure and manage low-carbon transitions. Yet – such centralising data infrastructures risk becoming part of systems that perpetuates historical marginalisation, rather than tools to address systemic injustice: and they risk further sidelining important other forms of knowledge that may be essential to navigate our shared future on a changing planet.
I’m drawn to thinking about the question of ‘minimum shared frameworks’ that may be needed both in national and global contexts to address the particular global challenge of the climate in which all our destines are intertwined. Yet, whilst I can imagine decentralised, (even decolonised?), systems of data capture, sharing and use in order to help accelerate a low-carbon transitions, I’m struggling at first-look to see how those might be brought into being at the pace required by the climate crisis.
Perhaps my focus for that should be on later lines of the Manyfesto:
“We seek to center the engineering, design, knowledge-production, and dispute-resolution practices of diverse cultures, which are embedded with their own value systems.”
My own cultural context, social role, academic training and temperament leaves me profoundly uncomfortable ending a piece of writing without a conclusion – even if a conclusion would be premature (one of the particular structures of the ‘Western male, white’ thought that perhaps does much harm). But, I suspect that here I need to simply take first steps into the dance, and to be more attuned to the way it flows…
[Summary: I’m trying to post a bit more critical reflection on things I read, and to write up more of my learning in shared space. I’ve been exploring why that’s been feeling difficult of late.]
Reading, blogging and engaging through social media used to be a fairly central part of my reflective learning practice. In recent years, my reading, note-taking and posting practices have become quite frayed. Although many times I get as far as a draft post or tweet thread of reflections, I’m often hit by a posting-paralysis – and I stop short both of engaging in open conversation, and solidifying my own reflections through a public post. As I return to a mix of freelance facilitation, research and project work (more on that soon), I’m keen to recover an open learning practice that makes effective use of online spaces
Inspired by Lloyd Davis’ explorations in ‘learning how to work out loud again’(appropriately so, since Lloyd’s earlier community convening and event hosting was a big influence on much of my earlier practice), I’m taking a bit of time in my first few days weeks back at work to identify what I want from a reflective learning practice, to try and examine the barriers I’ve been encountering, and to prototype the tools, processes and principles that might help me recapture some of the thinking space that, at it’s best, the online realm can still (I hope) provide.
Why post anyway?
The caption of David Eaves’ blog comes to mind: “if writing is a muscle, this is my gym”. And linked: writing is a tool of thought. So, if I want to think properly about the things I’m reading and engaging with, I need to be writing about them. And writing a blog post, or constructing a tweet thread, can be a very effective way to push that writing (and thinking) beyond rough bullet points, to more complete thoughts. Such posts often work well as external memory: more than once I’ve searched for an idea, and come upon a blog post I wrote about it many years ago – rediscovering content I might not have found had it been buried in a personal notebook. (It turns out comments from spam bots are also a good ‘random-access-memory-prompt’ on a wordpress blog.)
I’ve also long been influenced by my colleague Bill Badham’s commitment to shared learning. My work often affords me the privilege to read, research and reflect – and there’s something of an obligation to openly share the learning that arises. On a related note, I’m heavily influenced by notions of open academic debate, where there’s a culture (albeit not uncomplicated) of raising questions or challenging data, assumptions and conclusions in the interest of getting to better answers.
So what’s stopping you?
At risk of harking back to a golden age of RSS and blogging, that died along with Google Reader, I suspect I need to consciously adapt my practices to a changed landscape.
Online platforms have changed. I felt most fluent in a time of independent bloggers, slowly reading and responding to each other over a matter of days and weeks. Today, I discover most content via Tweets rather than RSS, and conversations appear to have a much shorter half-life, often fragmenting off into walled garden spaces, of fizzling out half completed as they get lost between different timezones. I’m reluctant to join discussions on walled garden platforms like Facebook, and often find it hard to form thoughts adequately in tweet length.
My networks have changed. At the macro level, online spaces (and public discourse more generally) feels more polarised and quick to anger: although I only find this when I voyage outside the relatively civil filter bubble of online I seem to have built. On the upside, I feel as thought the people I’m surrounded with online are more global, and more diverse (in part, from a conscious effort to seek more gender balance and diversity in who I follow): but on the flip-side, I’m acutely aware that when I write I can’t assume I’m writing into a common culture, or that what I intend as friendly constructive critique will be read as such. Linked to this:
I’m more aware of unintended consequences of a careless post. In particular, I’m aware that, as a cis white male online, I don’t experience even half of the background aggression, abuse, gaslighting or general frustration that many professional women, people of colour, or people from minority communities may encounter daily. What, for me, might be a quick comment on something I’ve read, could come across to others as ‘yet another’ critical comment rather than the ‘Yes, and’I meant it to be.
There are lots of subtleties to navigate around when an @ mention might be seen as a hat-tip credit, vs. when it might be an unwelcome interruption.
My role has changedI still generally think of myself as a learner and junior practitioner, just trying to think out loud. But I’ve become aware from a couple of experiences that sometimes people take what I write more seriously! And that can be a little bit scary, or can place a different pressure on what I’m writing. Am I writing for my own process of thinking? Writing for others? Or writing for impact? Will my critical commentary be taken as having a weight I did not intend? And at the times when I do intend to write in order to influence, rather than just offer a viewpoint, do I need different practices?
My capacity, and focus, has changedThe pandemic and parenthood have squeezed out many of the time-slots I used to use for reflective writing: the train back from London, the early evening and so-on. I’m trying to keep social media engagement to my working hours too, to avoid distractions and disruption during time with family.
Over editingA lot of the work I’ve done over recent years has involved editing text from others, and it’s made me less comfortable with the flow-of-writing, overly subclaused, and less-than-perfectly-clear sentences I’m prone to blogging with. (Though I can still resist that inner editor, as this mess of a paragraph attests: I am writing mainly for my own thinking after all.)
So what do I do about it?
Well – I’m certainly not over posting paralysis: this post has been sitting in draft for a week now. But in the process of putting it together I’ve been exploring a few things:
A more conscious reading practice
Improving my note-taking tools
Linking blogging and social media use
Not putting too much pressure on public posting
I’ve brought scattered notes from the last few years together into a tiddlywiki instance, and have started trying to keep a daily journal there for ad-hoc notes from articles or papers I’m reading – worrying less about perfect curation of notes, and more about just capturing reflections as they arise. I’ve reset my feed reader, and bookmarking tools to better manage a reading list, and am trying to think more carefully about the time to give to reading different things.
I’ve also tried getting back to a blog-post format for responding to things I’m reading, rather than trying twitter threads, which, whilst they might have a more immediate ‘reach’, often feel to me both a bit forced, and demand more immediate follow-up to engage with than my capacity allows.
I was considering setting myself an artificial goal of posting daily or weekly, but for now I’m going to allow a more organic flow of posting, and review in a few weeks to see if developing the diagnosis, and some of the initial steps above, are getting my practice closer to where I want it to be.