One of my first assignments now that I’m back working as an independent consultant was to support the Open Data Institute to develop a working paper on data, the built environment and climate action.
The draft paper was released on Monday, to coincide with the start of COP26, and ahead of the Open Data Institute’s Summit – and it will be open for comments and further input until 19th October.
Over here on Twitter I’ve put together a brief thread of some of the key messages in the report.
Thread: Built environment accounts for around 40% of the UK’s total carbon footprint (similar worldwide). Better data sharing has role to play in addressing operational (from use) & embodied (from construction) emissions, increasing transparency, & improving resilience. 1/n https://t.co/23fZCajAQ8pic.twitter.com/02qVztJl2z
[Summary: Fragments of reflection on the Decarbonisation and Decolonisation of AI]
I’ve spent some time this morning reading the ‘AI Decolonial Manyfesto’ which opens framed as “a question, an opening, a dance about a future of AI technologies that is decolonial”. Drawing on the insights, positions and perspectives of a fantastic collective authorship, it provides some powerful challenges for thinking about how to shape the future applications of AI (and wider data) technologies.
As I’ve been reading the Manyfesto on Decolonialisation in a short break from working on a project about Decabonisation – and the use of data and AI to mitigate and adapt to the pressing risks of climate breakdown, I find myself particularly reflecting on two lines:
“We do not seek consensus: we value human difference. We reject the idea that any one framework could rule globally.”
and
“Decolonial governance will recognize, in a way that Western-centric governance structures historically have not, how our destinies are intertwined. We owe each other our mutual futures.”
Discussions over the role of data in addressing the global climate crisis may veer towards proposing vast centralising data (and AI) frameworks (or infrastructures), in order to monitor, measure and manage low-carbon transitions. Yet – such centralising data infrastructures risk becoming part of systems that perpetuates historical marginalisation, rather than tools to address systemic injustice: and they risk further sidelining important other forms of knowledge that may be essential to navigate our shared future on a changing planet.
I’m drawn to thinking about the question of ‘minimum shared frameworks’ that may be needed both in national and global contexts to address the particular global challenge of the climate in which all our destines are intertwined. Yet, whilst I can imagine decentralised, (even decolonised?), systems of data capture, sharing and use in order to help accelerate a low-carbon transitions, I’m struggling at first-look to see how those might be brought into being at the pace required by the climate crisis.
Perhaps my focus for that should be on later lines of the Manyfesto:
“We seek to center the engineering, design, knowledge-production, and dispute-resolution practices of diverse cultures, which are embedded with their own value systems.”
My own cultural context, social role, academic training and temperament leaves me profoundly uncomfortable ending a piece of writing without a conclusion – even if a conclusion would be premature (one of the particular structures of the ‘Western male, white’ thought that perhaps does much harm). But, I suspect that here I need to simply take first steps into the dance, and to be more attuned to the way it flows…
In what I think is now the longest running series of posts on this blog, I’m back reviewing documents relating to Gloucestershire’s Javelin Park Incinerator saga (see here). This is a long and particularly wonky post, put together quickly ahead of tomorrow’s Audit Committee Meeting. I’ll try and draw out some of these ad-hoc observations into something more accessible soon.
In December 2018, GCC dropped an appeal to the Information Tribunal to keep the details of a revised 2016 contract secret, leading to the revelation of over £150m cost increase in the contract.
In January 2019, Community R4C issued legal proceedings based on the new information: calling for a renegotiation of the contract and nominal damages. Preliminary hearings for the case concluded in July 2020, with the judgement that CR4C did not have ‘standing’ to bring the case (i.e. as only ‘economic operators’ affected by a failing of procurement law can bring a case, the predominantly public-interest case brought by CR4C was ineligible.). CR4C appealed, but that appeal was rejected asked to appeal, but were denied permission to, [Correction: 29/09/21] in November 2020.
The audit report from Grant Thornton has been persistently delayed, in part due to a lack of information provision by the local authority and restrictions on sharing that information with the objectors, and since 2019, to allow conclusion of the court case.
The Auditors response stops short of issuing a ‘Report in the Public Interest’, and triggering the associated public meetings. This appears to be at odds with the outcome that the objectors, Community R4C had expected based on their access to earlier drafts of the report from the auditor which concluded that a Public Interest Report was required [Addition: 29/09/21].
This post is my notes from reading the auditors letter and report.
What does the report find?
In short, the auditors conclude that they cannot draw a definitive conclusion with respect to audit objections:
Because of the length of time passed since the contract was signed;
Because of the complexity of the contacts financial model, and the assumed cost of assessing whether it’s renegotiation in 2016 shifted the economic balance in favour of the operator (UBB);
Because other Energy from Waste contracts are not transparent, making comparison to other authority contracts difficult.
They write that:
” our main objective is to explain why we have not reached a definitive conclusion, rather than to express such a conclusion,”
although then then state that:
“we do not consider that anything further by way of public reporting and consideration by a Committee of the Council is required”
with perhaps an implicit suggestion it seems that the council wanted to avoid public reporting of this at all?
However, on the substantive matters, the report finds (page 12):
The council conclusively did not consider whether the 2016 renegotiation shifted the economic balance in favour of UBB
The auditors consider it would have been appropriate to conduct such an assessment and to keep records of it;
The auditor does not agree with the council’s legal opinion that it was not required to produce such an assessment, but accepts that the council was acting on its own legal advice.
They go on to say:
“From an audit perspective, a decision making process followed by a council which accorded with its legal view at the time is not in itself necessarily a cause for concern simply because that legal view may have been erroneous. Such a process does not necessarily indicate that the council lacks appropriate internal procedures for ensuring the sound management of its resources.”
So, whilst the council relying upon faulty legal advice for a 25-year contract appears not to be grounds for a negative independent audit conclusion – it should surely be a significant matter of serious concern for the Audit and Governance Committee.
Put another way, the auditors conclude that:
“Our view, in line with the advice we have received from independent Counsel, is that the material we have so far considered is insufficient to enable us to reach a firm conclusion as to the lawfulness under procurement law of the modifications.”
Which, although it appears nothing can now be done to exit the Javelin Park contract, leaves at 25-year, £600m commitments by Gloucestershire Taxpayers under a significant cloud.
Establishing the legality of their actions is surely the least we should expect from our local authorities, let alone establishing that they operate in the best-interests of local residents and the wider environment.
It is also notable that, had the authority not fought against disclosure of contract details until late 2018, more contemporary examination of the case may have been possible, lessening the auditors objection that too much time has passed to allow them to conduct a proper investigation. The auditor however studiously avoids this point by stating:
“It is not our function to ‘regulate’ the Council in terms of whether it is sufficiently committed to transparency, or whether it has unjustifiably refused to release information in response to Freedom of Information Act requests.”
Yet, transparency is a central part of our public governance arrangements (not least in supporting meaningful public engagement with audit objections), and for it to fall entirely outside the scope of auditors comments about whether processes were robust is notable.
Observations to explore further
As I’ve read through, a few different things have struck me – often in connection with past documents I’ve reviewed. I’ve made brief notes on each of these below.
On page 19, considering the impact of the contract on incentives to recycle states that:
“While the average cost per tonne does clearly reduce as the level of waste increases, which may be as a result of lower recycling rates, the Council does not have direct influence over recycling rates.”
A considerable part of the case the Council rely upon to prove Value for Money of the incinerator is the report produced by EY that compares the cost of the renegotiated 2016 contract with the cost of terminating the contract and relying on landfill for the next 25 years.
The auditors note that:
“the Council was professionally advised during the negotiation process, including by EY on the VfM of the RPP in comparison to terminating the contract and relying on landfill.”
However, the scope of the EY report, which compares to the “Council’s internal Landfill Comparator” (see covering letter) was set not on the expert advice of EY, but at the instruction of the Council’s procurement lead, Ian Mawdsley. As I established in a 2019 FOI, when I asked for:
the written instructions (as Terms of Reference, e-mail confirmation or other documentary evidence) of the work that was requested from Ernst and Young. Depending on the process of commissioning this work, I would anticipate it would form a written document, part of a work order, or an e-mail from GCC to E&Y.
and the council replied:
“We have completed our investigation into the points you raise and can confirm that the council do not hold any separate written terms of reference as these were initially verbal and recorded in the document itself.
It seems reasonable to me that an expert advisor, given scope to properly consider alternatives, may have been able to, for example, compare termination against short-term landfill, followed by re-procurement. This should have been informed by the outcome of the Residual Waste Working Group Fallback Strategy that considered alternatives in 2013, but appears to have been entirely ignored by the Council administration.
If the council is to rely on ‘expert advice’ to establish that it, in good faith, sought to secure value for money on the project – then the processes to commission that advice, and the extent to which consultants were given a brief that allowed them to properly consider alternatives, should surely be considered?
Cancellation costs are a range: where are the error bars?
The auditor briefly considers whether councillors were given accurate information when, in meetings in 2015, they were debating contract cancellation costs of £60m – £100m.
My reading of the EY report, is that, on the very last page, it gives a range of possible termination costs for force majeure planning permission-related termination, with the lowest being £35.4m (against a high of £69.8m). Higher up, it reports a single figure of £59.8m. The figure of £100m is quoted as relating to ‘Authority Voluntary Termination’ by EY note they have not calculated this figure in detail. It therefore seems surprising to me for the auditors to conclude that, a meeting in 2015 considering contract cancellation, that was not provided with an officer report explaining either figure, but being told that cancellation costs were in the range £60m to £100m was:
“not distorted by inaccurate information.”
As surely the accurate information that should have been presented would have simply been:
EY have produced estimated costs in a range from £35.4m – £69.8m if we cancel due to passing the planning long-stop date. Their best estimate for a single figure in this range of £59.8m
EY have produced a rough estimate (but no calculations) of a cost of £100m if the authority cancels for other reasons outside the panning delay.
The council estimates that sticking with landfill for a period of time, and carrying out another procurement exercise could add up to X to the cost.
Eversheds advice
Re-reading the EY report, I note that it refers to separate advice provided by Eversheds on the issues of State Aid, Documentation Changes and Procurement risks including risks of challenge.
To my knowledge this advice has never been put in the public domain. It may be notable however, that the auditor does not reference this advice in their reply on the objectors allegation that the contract could have constituted illegal state aid.
Perhaps another FOI request if someone else wants to pick up the baton on that?
We should have recorded meetings!
I was present at the March 2019 meeting when the chief executive admitted that the council were in a poor negotiating position in relation the contract. My partner, Cllr Smith, raised the failure of the minutes to include this point at the subsequent meeting but it appears the administration were already attempting to remove this admission from the record.
Whilst the auditor states:
“In our view, even assuming that such a statement was made by the Chief Executive (and we make no finding as to whether it was: we note that the Council does not accept that your record of the meeting is accurate), it would not in itself justify our making a finding that the contract modifications shifted the balance of the contract in UBB’s favour.”
That this point is addressed, and that the Council administration have attempted to keep admissions in a public meeting of their weak negotiation position from the record, is of note.
With hindsight, given the Council chose to hold this meeting in a room that was not webcast, we should have arranged independent citizen led recording of the meeting.
A problem with facts?
The final line of the auditors letter, in their reasons for not seeking to make an application to the court for a declaration that council acts may have been against the law is rather curious:
“the issues underlying these matters are very fact specific such that there would be limited wider public interest in a court declaration.”
An argument for or against Open Contracting?
The report appears to make a strong case for wholesale Open Contracting when it comes to large EfW projects. They state:
“We accept that the comparisons included in the WRAP report do have significant limitations, mainly because they are, as the Council notes, quoted at a point in time and in isolation from the underlying contractual terms such as length of contract, risk share etc. Without access to such information on the contracts in place elsewhere, it is impossible to do a conclusive comparison, and even with full information on the various contracts, there would still be a good many judgements and assumptions involved in making a comparison because of, for example, variations in the ‘values’ associated with particular risks.”
In other words – the lack of transparency in Energy from Waste projects makes it nearly impossible to verify that the waste ‘market’ (which, because of geographical constraints and other factors is a relatively inflexible market in any case), has generated value for money for the public.
I’m also not sure why ‘values’ gets scare quotes in the extract above…
However, it appears to me that, rather than calling for greater publication of contracts, the auditors want to go the other way, and argue that contracting transparency could be bad for local authorities:
“Procurement law pursues objectives that are wider than promoting the efficient use of public resources. In particular, procurement law, as applicable at the relevant time, sought to pursue EU internal market objectives and to ensure the compliance of EU member states with obligations under the World Trade Organisation Global Procurement Agreement, by ensuring that contract opportunities were opened up to competition and that public procurement procedures were non-discriminatory and transparent. In some circumstances, public procurement law could potentially operate to preclude an authority from selecting an approach which could reasonably be regarded by the authority as the most economically efficient option available to it in the circumstances.”
This critique of the laws ‘as applicable at the relevant time’ (i.e. during EU membership) also raises a potential red flag about arguments post-Brexit Britain may increasingly see.
Is Local Audit Independent and Effective?
I recall hearing some critique of Grant Thornton’s audit quality – and struck by some of my concerns about how this objection letter reads, did a brief bit of digging into the regulators opinion.
In 2019/20, the Financial Reporting Council reviewed six local audits by Grant Thornton. None were fully accepted, with the regulator concluding that:
Thee audit quality results for our inspection of the six audits are unacceptable, with five audits assessed as requiring improvement, although no audits were assessed as requiring significant improvement.
going on to note that:
“At least two key findings were identified on all audits requiring improvement and therefore areas of focus are the audit of property valuation, assessment and subsequent testing of fraud risks, audit procedures over the completeness and accuracy of expenditure and EQC review procedures.”
Whilst this does not cover assessment of the quality of reports in relation to audit objections, it is notable that in their response to the report Grant Thornton state:
“We consider that VfM audit is at the centre of local audit. We take VfM work seriously, invest time and resources in getting it right, and give difficult messages where warranted. In the last year, we have issued a Report in the Public Interest at a major audit, Statutory Recommendations and Adverse VfM Conclusions.”
Yet, in the Gloucestershire case, the auditors failed have studiously avoided asking any substantive Value for Money questions about the largest ever contract for the local authority, either at the time the contract was negotiated, or following concerns raised by objectors.
In their response to objectors, Grant Thornton rely a number of times on the time elapsed since the contract was signed as a reason that they cannot conduct any VfM analysis. Yet, they were the auditors at the time significant multi-million capital sums were committed the project: which surely should have triggered contemporary VfM questions?
It’s notable that local electors are being asked to trust that Grant Thornton have very robust processes in place to protect against conflict of interest, not only because a finding that VfM was not secured would surely call into question the comprehensiveness of Grant Thornton’s past audit work (none of which is referenced in the report) and because, as we learnt from the £1m Ernst and Young Report relied upon to assert that the council had sought suitable independent advice, the financial models of Incinerator operator UBB were written by, none other than, Grant Thornton.
One thing that has come across in years of reading the documents on this process, from Information Tribunal rulings, Court rulings and the Auditors letter, is the ‘frustration’ of the authorities (e.g. Judges, Auditors) being asked to ‘adjudicate’ in this case with one or other of the parties. At times, the Council has come in for thinly veiled or outright criticism for lack of co-operation, and Community R4C appear to have at times undermined their case by making what the auditors view as excessive or out-of-scope objections.
A few takeaways from this:
There is a high bar for citizen-objectors to clear in making effective objections, and little support for this. Community R4C have drawn on extensive pro-bono legal advice, crowd-funding and other resources – and yet their core case, that the project is neither Value for Money, nor in-line with the waste hierarchy, has never been properly heard: always ruled out of consideration on ‘technicalities’.
Objection processes need to be made more user-friendly: and at the same time, objectors need to be supported with advice and even intermediaries who can help support filtered and strategic use of public scrutiny powers.
The lack of openness from Gloucestershire County Council to dialogue has been perhaps the biggest cause of this saga running on: leading to frustrating, irritable and costly interactions through courts and auditors – rather than public discussion of constructive ways forward for waste management in the County.
Where next?
I’ll be interested to see the outcome of tomorrow’s meeting of the audit committee, where, even though there were only a few hours between the report and question deadline, I understand there will be a substantial number of public questions asked.
My sense is there still remains a strong case for an independent process to learn lessons from, what remains to my mind, a likely significant set of governance failures at Gloucestershire County Council, and to ensure future waste management is properly in line with the goal of increased recycling and waste reduction.
[Summary: I’m trying to post a bit more critical reflection on things I read, and to write up more of my learning in shared space. I’ve been exploring why that’s been feeling difficult of late.]
Reading, blogging and engaging through social media used to be a fairly central part of my reflective learning practice. In recent years, my reading, note-taking and posting practices have become quite frayed. Although many times I get as far as a draft post or tweet thread of reflections, I’m often hit by a posting-paralysis – and I stop short both of engaging in open conversation, and solidifying my own reflections through a public post. As I return to a mix of freelance facilitation, research and project work (more on that soon), I’m keen to recover an open learning practice that makes effective use of online spaces
Inspired by Lloyd Davis’ explorations in ‘learning how to work out loud again’(appropriately so, since Lloyd’s earlier community convening and event hosting was a big influence on much of my earlier practice), I’m taking a bit of time in my first few days weeks back at work to identify what I want from a reflective learning practice, to try and examine the barriers I’ve been encountering, and to prototype the tools, processes and principles that might help me recapture some of the thinking space that, at it’s best, the online realm can still (I hope) provide.
Why post anyway?
The caption of David Eaves’ blog comes to mind: “if writing is a muscle, this is my gym”. And linked: writing is a tool of thought. So, if I want to think properly about the things I’m reading and engaging with, I need to be writing about them. And writing a blog post, or constructing a tweet thread, can be a very effective way to push that writing (and thinking) beyond rough bullet points, to more complete thoughts. Such posts often work well as external memory: more than once I’ve searched for an idea, and come upon a blog post I wrote about it many years ago – rediscovering content I might not have found had it been buried in a personal notebook. (It turns out comments from spam bots are also a good ‘random-access-memory-prompt’ on a wordpress blog.)
I’ve also long been influenced by my colleague Bill Badham’s commitment to shared learning. My work often affords me the privilege to read, research and reflect – and there’s something of an obligation to openly share the learning that arises. On a related note, I’m heavily influenced by notions of open academic debate, where there’s a culture (albeit not uncomplicated) of raising questions or challenging data, assumptions and conclusions in the interest of getting to better answers.
So what’s stopping you?
At risk of harking back to a golden age of RSS and blogging, that died along with Google Reader, I suspect I need to consciously adapt my practices to a changed landscape.
Online platforms have changed. I felt most fluent in a time of independent bloggers, slowly reading and responding to each other over a matter of days and weeks. Today, I discover most content via Tweets rather than RSS, and conversations appear to have a much shorter half-life, often fragmenting off into walled garden spaces, of fizzling out half completed as they get lost between different timezones. I’m reluctant to join discussions on walled garden platforms like Facebook, and often find it hard to form thoughts adequately in tweet length.
My networks have changed. At the macro level, online spaces (and public discourse more generally) feels more polarised and quick to anger: although I only find this when I voyage outside the relatively civil filter bubble of online I seem to have built. On the upside, I feel as thought the people I’m surrounded with online are more global, and more diverse (in part, from a conscious effort to seek more gender balance and diversity in who I follow): but on the flip-side, I’m acutely aware that when I write I can’t assume I’m writing into a common culture, or that what I intend as friendly constructive critique will be read as such. Linked to this:
I’m more aware of unintended consequences of a careless post. In particular, I’m aware that, as a cis white male online, I don’t experience even half of the background aggression, abuse, gaslighting or general frustration that many professional women, people of colour, or people from minority communities may encounter daily. What, for me, might be a quick comment on something I’ve read, could come across to others as ‘yet another’ critical comment rather than the ‘Yes, and’I meant it to be.
There are lots of subtleties to navigate around when an @ mention might be seen as a hat-tip credit, vs. when it might be an unwelcome interruption.
My role has changedI still generally think of myself as a learner and junior practitioner, just trying to think out loud. But I’ve become aware from a couple of experiences that sometimes people take what I write more seriously! And that can be a little bit scary, or can place a different pressure on what I’m writing. Am I writing for my own process of thinking? Writing for others? Or writing for impact? Will my critical commentary be taken as having a weight I did not intend? And at the times when I do intend to write in order to influence, rather than just offer a viewpoint, do I need different practices?
My capacity, and focus, has changedThe pandemic and parenthood have squeezed out many of the time-slots I used to use for reflective writing: the train back from London, the early evening and so-on. I’m trying to keep social media engagement to my working hours too, to avoid distractions and disruption during time with family.
Over editingA lot of the work I’ve done over recent years has involved editing text from others, and it’s made me less comfortable with the flow-of-writing, overly subclaused, and less-than-perfectly-clear sentences I’m prone to blogging with. (Though I can still resist that inner editor, as this mess of a paragraph attests: I am writing mainly for my own thinking after all.)
So what do I do about it?
Well – I’m certainly not over posting paralysis: this post has been sitting in draft for a week now. But in the process of putting it together I’ve been exploring a few things:
A more conscious reading practice
Improving my note-taking tools
Linking blogging and social media use
Not putting too much pressure on public posting
I’ve brought scattered notes from the last few years together into a tiddlywiki instance, and have started trying to keep a daily journal there for ad-hoc notes from articles or papers I’m reading – worrying less about perfect curation of notes, and more about just capturing reflections as they arise. I’ve reset my feed reader, and bookmarking tools to better manage a reading list, and am trying to think more carefully about the time to give to reading different things.
I’ve also tried getting back to a blog-post format for responding to things I’m reading, rather than trying twitter threads, which, whilst they might have a more immediate ‘reach’, often feel to me both a bit forced, and demand more immediate follow-up to engage with than my capacity allows.
I was considering setting myself an artificial goal of posting daily or weekly, but for now I’m going to allow a more organic flow of posting, and review in a few weeks to see if developing the diagnosis, and some of the initial steps above, are getting my practice closer to where I want it to be.
Below I’ve shared a few quick notes in a spirit of open reflection (read mostly as ‘Yes, and…‘ rather than ‘No, but’):
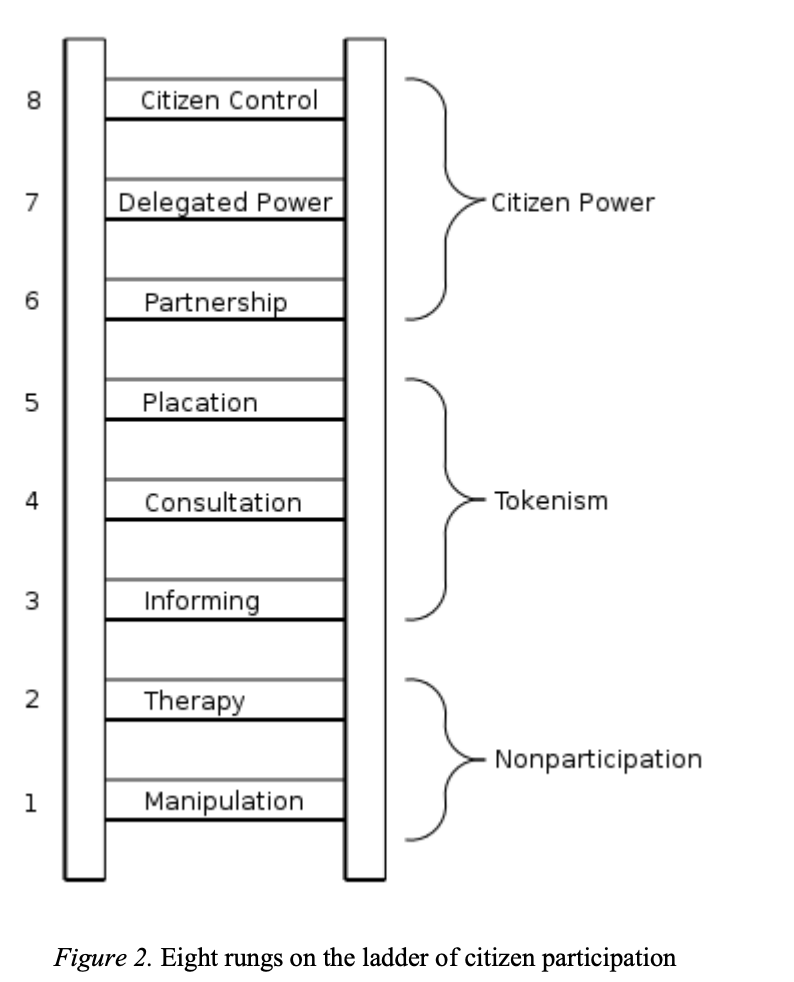
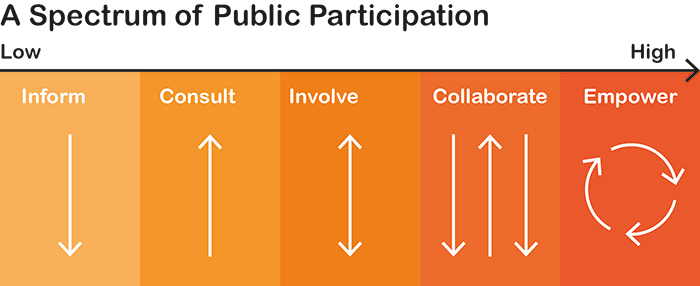
The ladder: Arnstein, Hart and Pathways of Participation
Arnstein’s ladder of participation.RSA ‘Remix’ of Arnstein
The report describes drawing on Sherry Arnstein’s ‘ladder of citizen participation’, but in practice uses an RSA simplification of the ladder into a five-part spectrum that cuts off the critical non-participation layers of Arnstein’s model. In doing this, it removes some of the key critical power of the original ladder as a tool to call out tokenism, and push for organisations to reach the highest appropriate rung that maximises the transfer of power.
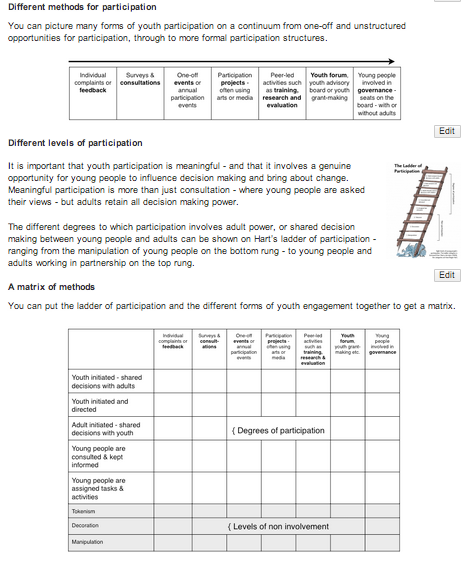
I’ve worked with various remixes of Arnstein’s ladder over the years, particularly building on building on Hart’s youth engagement remix) that draws attention to distinction between ‘participant initiated’ vs. ‘organisationally initiated’ decision making. In one remix we put forward with Bill Badham and the NYA Youth Participation Team we set the ladder against the range of methods of participations, and explored the need for any participation architecture to think about the pathways of participation through which individuals grow in their capacity to exercise power over decisions.
It would be great to see further developments of the Ada Lovelace framework consider the mix of participatory methods that are appropriate to certain data use contexts, and how these can be linked together. For example, informing all affected stakeholders about a data use project can be the first rung on the ladder towards a smaller number becoming co-designers, joint decision makers, or evaluators. And to design a meaningful consultation reaching a large proportion of affected stakeholders might require co-design or testing with a smaller group of diverse collaborators first: making sure that questions are framed and explained in legitimate and accessible ways.
Data collection, datasets, and data use
“Well-managed data can support organisations, researchers, governments and corporations to conduct lifesaving health research, reduce environmental harms and produce societal value for individuals and communities. But these benefits are often overshadowed by harms, as current practices in data collection, storage, sharing and use have led to high-profile misuses of personal data, data breaches and sharing scandals.”
It feels to me as though the report falls slightly (though, to be fair, not entirely) into the trap of seeing data as a pre-existing fixed resource, where the main questions to be discussed are who will access a dataset, on what terms and to what end. Yet, data is under constant construction, and in participatory data stewardship there should perhaps be a wider set of questions explicitly on the table such as:
Should this data exist at all?
How can this data be better collected in ways that respect stakeholders needs?
What data is missing that should be here? Are we considering the ‘lost opportunites’ as well as the risks of misuse?
Is this data structured in ways that properly represent the interests of all stakeholders?
Personally, I’m particularly interested in the governance role of data standards and structures, and exploring models to increase diverse participation in shaping these foundational parts of data infrastructure.
Decentering the dataset
The report argues that:
“There are currently few examples of participatory approaches to govern access and use of data…”
yet, I wonder if this comes from looking through a narrow lens for projects that are framed as just about the data. I’d hazard that there are numerous social change and public sector improvement projects have drawn upon data-sharing partnerships – albeit framed in terms of service or community change, rather than data-sharing per-se.
In both understanding existing practice, and thinking about the future of participatory data governance practices, I suspect we need to look at how questions about data use are embedded within wider questions about the kinds of change we are seeking to create. For example, if a project is planning to pool data from multiple organisations to identify ‘at risk families’ and to target interventions, a participatory process should take in both questions of data governance and intervention design – as to treat the data process in issolation of the wider use process makes for a less accessible, and potentially substantially biased, process.
Direct participation vs. representatives
One of the things the matrix of (youth) participation model tries to draw out is the distinction between participatory modalities based on ad-hoc individual involvement where stakeholders participate directly, through to those that involve sustained patterns of engagement, but that often move towards models of representative governance. Knowing whether you are aiming for direct or representative-driven participation is an important part of then answering the question ‘Who to involve?’, and being clear on the kind of structures needed to then support meaningful participation.
Where next?
It’s great to see participatory models of data governance on the agenda of groups like Ada Lovelace – although it also feels like there’s a way still to go to see many decades learning from the participation field better connecting with the kinds of technical decisions that affect so many lives.
Five years ago this week we lost our first daughter to a late miscarriage.I quietly collapsed. Unable to write, I abandoned my PhD dissertation – and have rarely felt fluent in writing since. We named our daughter Hope, because, after a long-time trying to conceive, she had given us hope of having a family.Over the next two years we had two more miscarriages. I put my energy into work and politics. In 2019, walking the Coast to Coast route, we decided to explore adoption. Later this year we’re hoping to be granted an adoption order for two children placed with us last Autumn.
I’ve tried, and failed, to write about these experiences before. Miscarriage is a complicated and often very private loss. Adoption equally lacks simple narratives: in many cases everyone, adult and child, come to it from a place of both loss and of hope. All stories involving family are shared stories where each party to them has different experiences, needs for acknowledgement, and needs for privacy. And adopting during a pandemic complicates the hope of building new family, with the loss of normal social interactions and clarity about the future.
However, to leave these experiences out of the public ‘biography’ created through various writings and work here or elsewhere, creates a gap in my own story that I’ve found increasingly difficult: particularly as my focus in the coming years will be much more on the equal parenting two children with my partner than on the kinds of projects and work I’ve done in the past. As this comes to transform both what I work on and how, there is both hope for new adventures and growth, and a loss to acknowledge, familiar to many parents I’m sure, of established identity, roles and routines.
As the personal is never separate from the social, I also find it important to recognise the last year as one of profound societal and individual losses across the world: both directly from the pandemic, and from the wider environmental and political challenges it has placed into sharp relief. At the same time, the last year has provided glimpses of hope for new ways of living more connected and sustainable lives.
Returning to the personal: in many ways, it feels as though my last five years have been a time of living with loss, but acting with hope. I look towards future years of living with hope, but acting everyday in recognition of, and learning from, loss.
Coda
In the short liturgy we held to remember our first daughter, we used words from Emily Dickinson that I’m now reminded of daily when our children take joy in seeing the birds in the garden:
[Summary: Reflections on the design of ITU Data Pledge project]
The ITU, under their “Global Initiative on AI and Data Commons” have launched a process to create a ‘Data Pledge’, designed as a mechanism to facilitate increased data sharing in order to support “response to humanity’s greatest challenges” and to ”help support and make available data as a common global resource.”.
Described as complementary to existing work such as the International Open Data Charter, the Pledge is framed as a tool to ‘collectively make data available when it matters’, with early scoping work discussing the idea of conditional pledges linked to ‘trigger events’, such that an organisation might promise to make information available specifically in a disaster context, such as the current COVID-19 Pandemic. Full development of the Pledge is taking place through a set of open working groups.
This post briefly explores some of the ways in which a Data Pledge could function, and considers some of the implications of different design approaches.
[Context: I’ve participated in one working group call around the data pledge project in my role as Project Director of the Global Data Barometer, and this is written up in a spirit of open collaboration. I have no formal role in the data pledge project..]
Governments, civil society or private sector
Should a pledge be tailored specifically to one sector? Frameworks for governments to open data are already reasonably well developed, as our mechanisms that could be used for governments to collaborate on improving standards and practices of data sharing.
However, in the private sector (and to some extent, in Civil Society), approaches to data sharing for the public good (whether as data philanthropy, or participation in data collaboratives are much less developed – and are likely the place in which a new initiative could have the greatest impact.
Individual or collective action problems
PledgeBank, a MySociety project that ran from 2005 to 2015, explored the idea of pledging as a solution to collective action problems. Pledges of the form: “I’ll do something, if a certain number of people will help me” are now familiar in some senses through crowdfunding sites and other online spaces. A Data Pledge could be modelled on the same logic – focussing on addressing those collective action problems either where:
A single firm doesn’t want to share certain data because doing so, when no-one else is, might have competitive impacts: but if a certain share of the market are sharing this data, it no longer has competitive significance, and instead it’s public good value can be realised.
The value of certain data is only realised as a result of network effects, when multiple firms are sharing similar and standardised data – but the effort of standardising and sharing data is non-negligible. In these cases, a firm might want to know that there is going to be a Social Return on Investment before putting resources into sharing the data.
However, this does introduce some complexity into the idea of pledging (and the actions pledged) and might, as PledgeBank found, lead also to lots of unrealised potential.
Pledging can also be approached as a means of solving individual motivational problems: helping firms to overcome inertia that means they are not sharing data which could have social value. Here, a pledge is more about making a statement of intent, which garners positive attention, and which commits the firm to a course of action that should eventually result in shared data.
Both forms of pledging can function as useful signalling – highlighting data that might be available in future, and priming potential ecosystems of intermediaries and users.
An organisational or dataset-specific pledge
Should a Pledge be about a general principle of data sharing for social good? Or about sharing a specific dataset? It may be useful to think about the architecture of the Data Pledge involving both: or at least, optionally involving data-specific pledges, under a general pledge to support data sharing for social good.
Think about organisational dynamics. Individual teams in a large organisation may have lots of data they could safely and appropriately share more widely for social good uses, but they do not feel empowered to even start thinking about this. A high-level organisational pledge (e.g. “We commit to share data for social good whenever we can do so in ways that do not undermine privacy or commercial position”) that sets an intention of a firm to support data philanthropy, participate in data collaboratives, and provide non-competitive data as open data, could provide the backing that teams across the organisation need to take steps in that direction.
At the same time, there may be certain significant datasets and data sources that can only be shared with significant high-level leadership from the organisation, or where signalling the specific data that might be released, or purposes it might be released for, can help address the collective action issues noted above. For these, dataset specific pledging (e.g. “We commit to share this specific dataset for the social good in circumstance X ”) can have significant value.
Triggers as required or optional
Should a pledge be structured to place emphasis on ‘trigger conditions’ for data sharing? Some articulations of the Data Pledge appear to think of it as a bank of data that could be shared in particular crisis situations. E.g. “We’ll share detailed supply chain information for affected areas if there is a disaster situation.”.There are certainly datasets of value that might not be listed as a Pledge unless trigger conditions can be described, but it’s important that the design of a pledge does not present triggers as essentially shifting any of the work on data sharing to some future point. Preparing for data to be used well and responsibly in a crisis situation requires work in advance of the trigger events: aligning datasets, identifying how they might be used, and accounting carefully for possible unintended consequences that need to be mitigated against.
There are also many global crisis we face that are present and ongoing: the climate crisis, migration, and our collective failure to be on track against the Sustainable Development Goals.
Brokering and curating
Data is always about something, and different datasets exist within (and across) different data communities and cultures. To operationalise a pledge will involve linking actors pledging to share data into relevant data communities: where they can understand user needs in more depth, and be able to publish with purpose.
The architecture of a Data Pledge, and of any supporting initiative around it, will need to consider how to curate and connect the many organisations that might engage – building thematic conversations, spotting thematic spaces where a critical mass of pledges might unlock new social value, or identifying areas where there are barriers stopping pledges turning into data flows.
Incorporating context, consent and responsible data principles
Increased data sharing is not an unalloyed good. Approaching data for the public good involves balancing openness and sharing, with robust principles and practices of data protection and ethics, including attention to data minimisation, individual rights, group data privacy, indigenous data sovereignty and dataset bias. Data should also be shared with clear documentation of it’s context, allowing an understanding of its affordances and limitations, and supporting debate over how data ecosystems can be improved in service of social justice.
A Pledge has an opportunity to both set the bar for responsible data practice, and to incentivise organisational thinking about these issues, by including terms that require pledging organisations to uphold high standards of data protection, only sharing personal data with clear informed consent or personal-derived data after clear processes that consider privacy, human rights and bias impacts of data sharing. Similarly, organisations could be asked to commit to putting their data in context when it is shared, and to engaging collaboratives with data users.
There may also be principles to incorporate here about transparency of data sharing arrangements – supporting development of norms about publishing clearly (a) who data is shared with and for what purpose; and (b) the privacy impact assessments carried out in advance of such shares.
Conditional on capacity?
Should pledging organisations be able to signal that they would need resources in order to make certain data available? I.e. We have Dataset X which has a certain social value: but we can’t afford to make this available with our internal resources? For low-resource organisations, including SMEs or organisations operating in low income economies, this could be a way to signal to philanthropic projects like data.org a need for support. But it could also be used by higher-resource organisations to put a barrier in front of data sharing. However, if a Pledge targets civil society pledgees, then allowing some way to indicate capacity needs if data is to be shared is likely to be particularly important.
A synthesis sketch
Whilst ideologically, I’d favour a focus on building and governing data commons, more directly addressing the modern ‘enclosure’ of data by private firms, and not forgetting the importance of proper taxation of data-related businesses to finance provision of public goods, if it’s viable to treat a data pledge as a pragmatic tool to increase availability for data for social good uses, then I’d sketch the following structure:
Target private sector organisations
A three part pledge
1. A general organisational commitment to treat data as a resource for the public good;
2. A linked organisational commitment to responsible data practices whenever sharing data;
3. An optional set of dataset specific pledges, each with optional trigger conditions
A platform allowing pledging organisations to profile their pledges, detail contact points for specific datasets and contact points for organisation-wide data stewards, and to connect with potential data users;
A programme of work to identify pre-work needed to allow data to be effectively used if trigger conditions are met ;
The only narrative of Rhodes I recall from that time, was one of the college’s proud connection to its alumni and benefactor. To my shame, whilst with student campaigners I was active against contemporary donations to the University that appeared to buy naming rights and launder the reputations of questionable modern day donors – I left unexplored how the ongoing honouring of past donors had allowed them to ‘buy’ a ‘controversial reputation’ instead of the condemnation their actions deserve. Nor did I consider then how the memorialisation of Rhodes plays a part (even if small compared to other factors) in perpetuating the continued exclusion of marginalised communities from Oxford, and in reinforcing barriers to people from (Oxford) minorities taking greater ownership over the institutions of the University.
The college has a (belated) opportunity to make the right statement with the removal of the Rhodes statue. Leave it there, and Rhodes remains a ‘controversial figure’ and the college an institution concerned only with reproducing “an educated ruling class” (to quote from the college’s essay on Rhodes). Move it to a museum where it belongs, and the conversation with every undergraduate can be about our importance of questioning and learning from history – using education as a means of creating a more just future. The teachable moment will be all the stronger when the statue’s niche stands empty.
[Summary: Exploring inclusion impacts of data and standards in response to a paper on Open Contracting & inclusion]
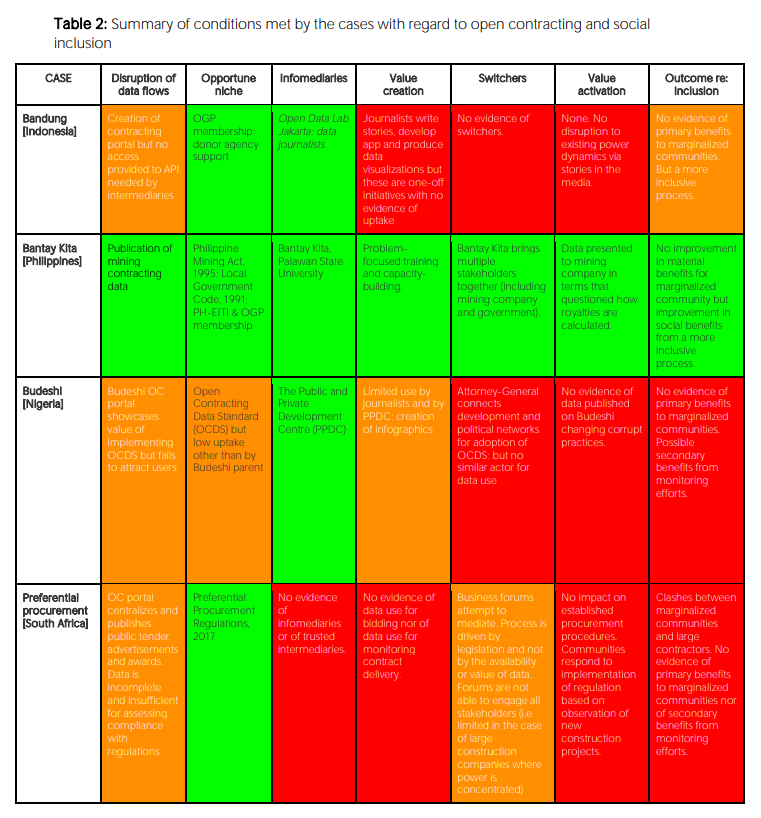
Yesterday I had the pleasure of joining a call hosted by HIVOS, and chaired by ILDA’s Ana Sofia Ruiz, to discuss a recent paper from Michael Canares and François van Schalkwyk on “Open Contracting and Inclusion”. The paper is well worth a read, and includes a review of five cases against a theoretical framework looking across data flows, opportunities for action, infomediary presence, and through to inclusion outcomes (see table below for example of how these play out in a few of the cases reviewed)
After the discussion, we were asked to summarise some of our inputs – hopefully feeding into a wide write-up. However, in case what I’ve written up doesn’t really fit the format of that, I’m posting a cleaned up and slightly expanded version of the remarks I made below:
This paper, and the discussion around it, raises a number of valuable questions – drawing on a rich theoretical landscape to post them.
Firstly, it asks us “How are data flows being disrupted?”. This question is important, because in many ‘open contracting’ projects it is rarely explicitly asked. We’re living in a time of mass disruption, yet open contracting is often ‘sold’ as a kind of reform. One of the widely used success stories for work on open contracting data comes from Ukraine, where there was a true disruption in data flows – using the moment of revolution to reconfigure patterns of procurement, and to create data infrastructures that enabled those new more open practices.
Secondly, this paper calls on us to question “what is the value of data in bringing about inclusion?” In the past we’ve talked about whether open data is either necessary or sufficient to create change. The answer I take from this paper is that increased accessibility of information and data is ‘a very useful, but nowhere near sufficient’ condition for inclusive change.
Thirdly, the use of Castell’s framework from Communication Power of ‘network power’ (shaping the information that can be transmitted), ‘networking power’ (gatekeeping which information is transmitted), and ‘networked power’ (control by one node in the network of others), and ideas of ‘programming the network’ and ‘reprogramming the network’, raise some critical questions about the role of data standards. Often treated as neutral artefacts, standards are in fact sites of power, and of the negotiation of network and networking power. A standard defines what can be expressed, and its implementation involves choosing what will be expressed. Standards can be at once tools that cross contexts, taking with them the potential of inclusion and exclusion (network power), and at the same time, have that potential left inert if the localised networking power decides not to take up inclusion oriented features.
To put this more concretely (if still a little complex I fear), the Open Contracting Data Standard was explicitly designed with a technical architecture that permits data about any given contracting process to be published by any actor, not only the ‘official’ information provider, and with a mechanism for extensions, supporting new fields of data to be attached to a contracting process. The ‘protocol’ sought to be inclusive. However, in practice, most tools have not been built to exploit this feature – meaning that in practice, the ‘platforms’ that exist don’t support inclusion of alternative perspectives on the state of a contracting process. This highlights that even at the level of the technical infrastructures, these are not made once, but have to be constantly remade, and their inclusive potential reinforced.
Fourth, the paper calls for a renewed focus on both governance context, and on intermediaries. Whilst technical artefacts can cross contexts, intermediary capacity building needs significant investment setting-by-setting. Equally, the discussion brought into view that this cannot be a short-term process. Intermediaries need not only skills, but also stocks of trust, in order to broker connections and communication. One of the evaluation team who had worked on a case covered by the paper discussed how it was individuals’ ability to maintain trusted relationships across different stakeholder groups that was critical to connecting information and empowerment. The importance of this cannot be overstated.
Fifth, and finally, in his opening statement, Michael Canares challenged us to consider whether Open Contracting is different from other public sector reforms? After all – there have been decades of procurement reform. To this, I’m prepared to advance an answer: There is a meaningful qualitative difference with government reforms that start from the premise of openness. When a commitment to being open by default is put into practice, the configuration of actors involved in creating change is different, and conventional patterns of bureaucratic reform can be disrupted. Whether they are disrupted or not depends still on individual internal and external actors, and on whether the culture, as well as the practice, of openness has been brought into play. Nevertheless, Open Contracting has certain potential that is simply absent from past procurement reforms – and that is something to continue to build on.
The challenge ahead now is to work out what to do with these questions. We’re starting to unpack the complexity of open contracting practice – and the nuances for each individual setting. But, if all we have are critical questions, we risk inaction rather than advances in inclusion. During the early development of the Open Contracting Data Standard we often turned to the mantra that we should not let the perfect be the enemy of the good. This carries forward: as we avoid the perfect being the enemy of making things better. I’d contend that we need to continue turning our learning into tooling – whether technical tools, evaluation frameworks, to simple planning tools for new initiatives. Only then can we be part of taking on the large scale reforms that this time of disruption needs.
[Summary: following the Bellagio Center thematic month on AI last year, I was asked to write up some brief notes on where data standards fit into contemporary debates on AI governance. The below article has just been published in the Rockefeller ‘notebook’ AI+1: Shaping our Integrated Future*]
Modern AI was hailed as bringing about ‘the end of theory’. To generate insight and action no longer would we need to structure the questions we ask of data. Rather, with enough data, and smart enough algorithms, patterns would emerge. In this world trained AI models would give the ‘right’ outcomes, even if we didn’t understand how they did this.
Today this theory-free approach to AI is under attack. Scholars have called out the ‘bias in, bias out’ problem of machine-learning systems, showing that biased datasets create biased models — and, by extension, biased predictions. That’s why policy makers now demand that if AI systems are used to make public decisions, their models need to be ‘explainable’, offering justifications for the predictions they make.
Yet, a deeper problem is rarely addressed. It is not just the selection of training data, or the design of algorithms, that embeds bias and fails to represent the world we want to live in. The underlying data structures and infrastructures on which AI is founded were rarely built with AI uses in mind, and the data standards — or lack thereof — used by those datasets place hard limits on what AI can deliver.
Questionable assumptions
From form fields for gender that only offer a binary choice, to disagreements over whether or not a company’s registration number should be a required field when applying for a government contract, data standards define the information that will be available to machine-learning systems. They set in stone hidden assumptions and taken-for-granted categories that make possible certain conclusions, while ruling others out, before the algorithm even runs. Data standards tell you what to record, and how to represent it. They embody particular world views, and shape the data that shapes decisions.
For corporations planning to use machine-learning models with their own data, creating a new data field or adapting available data to feed the model may be relatively easy. But for the public good uses of AI, which frequently draw on data from many independent agencies, individuals or sectors, syncing data structures is a challenging task.
Opening up AI infrastructure
However, there is hope. A number of open data standards projects have launched since 2010.
They include the International Aid Transparency Initiative (IATI) — which works with international aid donors to encourage them to publish project information in a common structure — and HXL, the Humanitarian eXchange Language, which offers a lightweight approach to structure spreadsheets with ‘Who, What, Where’ information from different agencies engaged in disaster response activities.
When these standards work well, they allow a broad community to share data that represents their own reality, and make data interoperable with that from others. But for this to happen, standards must be designed with broad participation so that they avoid design choices that embed problematic cultural assumptions, create unequal power dynamics, or strike the wrong balance between comprehensive representation of the world and simple data preparation. Without the right balance certain populations may drop out of the data sharing process altogether.
To use AI for the public good, we need to focus on the data substrata on which AI systems are built. This requires a primary focus on data standards, and far more inclusive standards development processes. Even if machine learning allows us to ask questions of data in new ways, we cannot shirk our responsibility to consciously design data infrastructures that make possible meaningful and socially just answers.
*I’ve only got print copies of the publication right now: happy to share locally in Stroud, and will update with a link to digital versions when available. Thanks to Dor Glick at Rockefeller for the invite and brief for this piece, and to Carolyn Whelan for editing.